mirror of
https://github.com/AbdBarho/stable-diffusion-webui-docker.git
synced 2025-10-28 08:44:33 -04:00
Compare commits
5 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
5eae2076ce | ||
|
|
725e1f39ba | ||
|
|
ab651fe0d7 | ||
|
|
f76f8d4671 | ||
|
|
e32a48f42a |
25
.github/workflows/docker.yml
vendored
25
.github/workflows/docker.yml
vendored
@@ -1,24 +1,15 @@
|
||||
name: Build Image
|
||||
name: Build Images
|
||||
|
||||
on: [push]
|
||||
|
||||
# TODO: how to cache intermediate images?
|
||||
jobs:
|
||||
build_hlky:
|
||||
build_all:
|
||||
runs-on: ubuntu-latest
|
||||
name: hlky
|
||||
name: All
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- run: docker compose build --progress plain
|
||||
build_AUTOMATIC1111:
|
||||
runs-on: ubuntu-latest
|
||||
name: AUTOMATIC1111
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- run: cd AUTOMATIC1111 && docker compose build --progress plain
|
||||
build_lstein:
|
||||
runs-on: ubuntu-latest
|
||||
name: lstein
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- run: cd lstein && docker compose build --progress plain
|
||||
# better caching?
|
||||
- run: docker compose --profile auto build --progress plain
|
||||
- run: docker compose --profile hlky build --progress plain
|
||||
- run: docker compose --profile lstein build --progress plain
|
||||
- run: docker compose --profile download build --progress plain
|
||||
|
||||
@@ -1,4 +0,0 @@
|
||||
{
|
||||
"outdir_samples": "/output",
|
||||
"font": "DejaVuSans.ttf"
|
||||
}
|
||||
@@ -1,20 +0,0 @@
|
||||
version: '3.9'
|
||||
|
||||
services:
|
||||
model:
|
||||
build: .
|
||||
ports:
|
||||
- "7860:7860"
|
||||
volumes:
|
||||
- ../cache:/cache
|
||||
- ../output:/output
|
||||
- ../models:/models
|
||||
environment:
|
||||
- CLI_ARGS=--medvram --opt-split-attention
|
||||
deploy:
|
||||
resources:
|
||||
reservations:
|
||||
devices:
|
||||
- driver: nvidia
|
||||
device_ids: ['0']
|
||||
capabilities: [gpu]
|
||||
89
README.md
89
README.md
@@ -2,84 +2,58 @@
|
||||
|
||||
Run Stable Diffusion on your machine with a nice UI without any hassle!
|
||||
|
||||
This repository provides the [WebUI](https://github.com/hlky/stable-diffusion-webui) as a docker image for easy setup and deployment.
|
||||
|
||||
Now with experimental support for 2 other forks:
|
||||
|
||||
- [AUTOMATIC1111](./AUTOMATIC1111/) (Stable, very few bugs!)
|
||||
- [lstein](./lstein/)
|
||||
|
||||
NOTE: big update coming up!
|
||||
This repository provides multiple UIs for you to play around with stable diffusion:
|
||||
|
||||
## Features
|
||||
|
||||
- Interactive UI with many features, and more on the way!
|
||||
- Support for 6GB GPU cards.
|
||||
- GFPGAN for face reconstruction, RealESRGAN for super-sampling.
|
||||
- Experimental:
|
||||
- Latent Diffusion Super Resolution
|
||||
- GoBig
|
||||
- GoLatent
|
||||
- many more!
|
||||
### AUTOMATIC1111
|
||||
|
||||
## Setup
|
||||
[AUTOMATIC1111's fork](https://github.com/AUTOMATIC1111/stable-diffusion-webui) is imho the most feature rich yet elegant UI:
|
||||
|
||||
Make sure you have an **up to date** version of docker installed. Download this repo and run:
|
||||
- Text to image, with many samplers and even negative prompts!
|
||||
- Image to image, with masking, cropping, in-painting, out-painting, variations.
|
||||
- GFPGAN, RealESRGAN, LDSR, CodeFormer.
|
||||
- Loopback, prompt weighting, prompt matrix, X/Y plot
|
||||
- Live preview of the generated images.
|
||||
- Highly optimized 4GB GPU support, or even CPU only!
|
||||
- [Full feature list here](https://github.com/AUTOMATIC1111/stable-diffusion-webui-feature-showcase)
|
||||
|
||||
```
|
||||
docker compose build
|
||||
```
|
||||
| Text to image | Image to image | Extras |
|
||||
| ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- |
|
||||
|  |  | 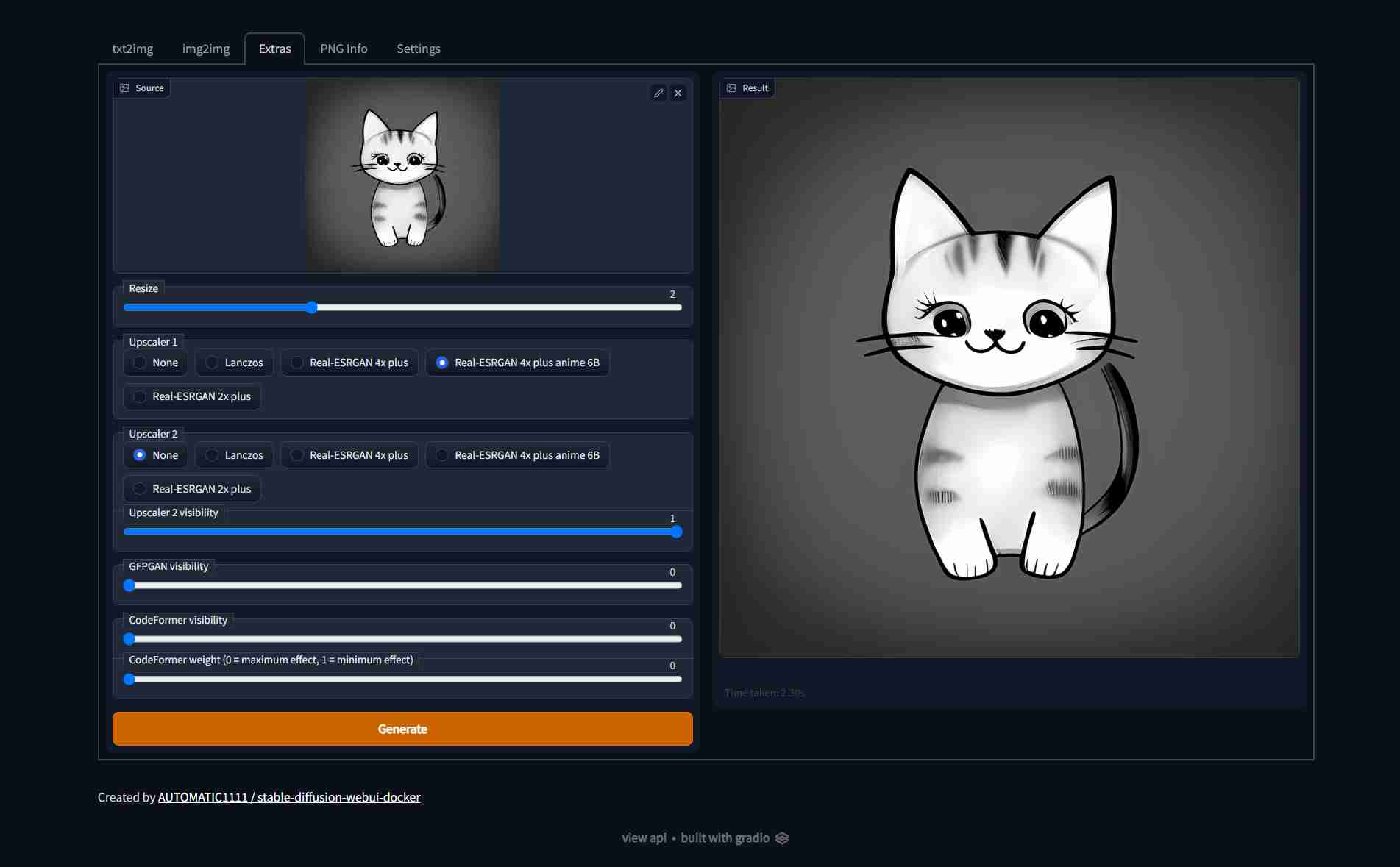 |
|
||||
|
||||
you can let it build in the background while you download the different models
|
||||
### hlky
|
||||
|
||||
- [Stable Diffusion v1.4 (4GB)](https://www.googleapis.com/storage/v1/b/aai-blog-files/o/sd-v1-4.ckpt?alt=media), rename to `model.ckpt`
|
||||
- (Optional) [GFPGANv1.3.pth (333MB)](https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.3.pth).
|
||||
- (Optional) [RealESRGAN_x4plus.pth (64MB)](https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth) and [RealESRGAN_x4plus_anime_6B.pth (18MB)](https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.2.4/RealESRGAN_x4plus_anime_6B.pth).
|
||||
- (Optional) [LDSR (2GB)](https://heibox.uni-heidelberg.de/f/578df07c8fc04ffbadf3/?dl=1) and [its configuration](https://heibox.uni-heidelberg.de/f/31a76b13ea27482981b4/?dl=1), rename to `LDSR.ckpt` and `LDSR.yaml` respectively.
|
||||
<!-- - (Optional) [RealESRGAN_x2plus.pth (64MB)](https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.1/RealESRGAN_x2plus.pth)
|
||||
- TODO: (I still need to find the RealESRGAN_x2plus_6b.pth) -->
|
||||
[hlky's fork](https://github.com/hlky/stable-diffusion-webui) is one of the most popular UIs, with many features:
|
||||
|
||||
Put all of the downloaded files in the `models` folder, it should look something like this:
|
||||
- Text to image, with many samplers
|
||||
- Image to image, with masking, cropping, in-painting, variations.
|
||||
- GFPGAN, RealESRGAN, LDSR, GoBig, GoLatent
|
||||
- Loopback, prompt weighting
|
||||
- 6GB or even 4GB GPU support!
|
||||
- [Full feature list here](https://github.com/sd-webui/stable-diffusion-webui/blob/master/README.md)
|
||||
|
||||
```
|
||||
models/
|
||||
├── model.ckpt
|
||||
├── GFPGANv1.3.pth
|
||||
├── RealESRGAN_x4plus.pth
|
||||
├── RealESRGAN_x4plus_anime_6B.pth
|
||||
├── LDSR.ckpt
|
||||
└── LDSR.yaml
|
||||
```
|
||||
Screenshots:
|
||||
|
||||
## Run
|
||||
| Text to image | Image to image | Image Lab |
|
||||
| ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- |
|
||||
|  |  | 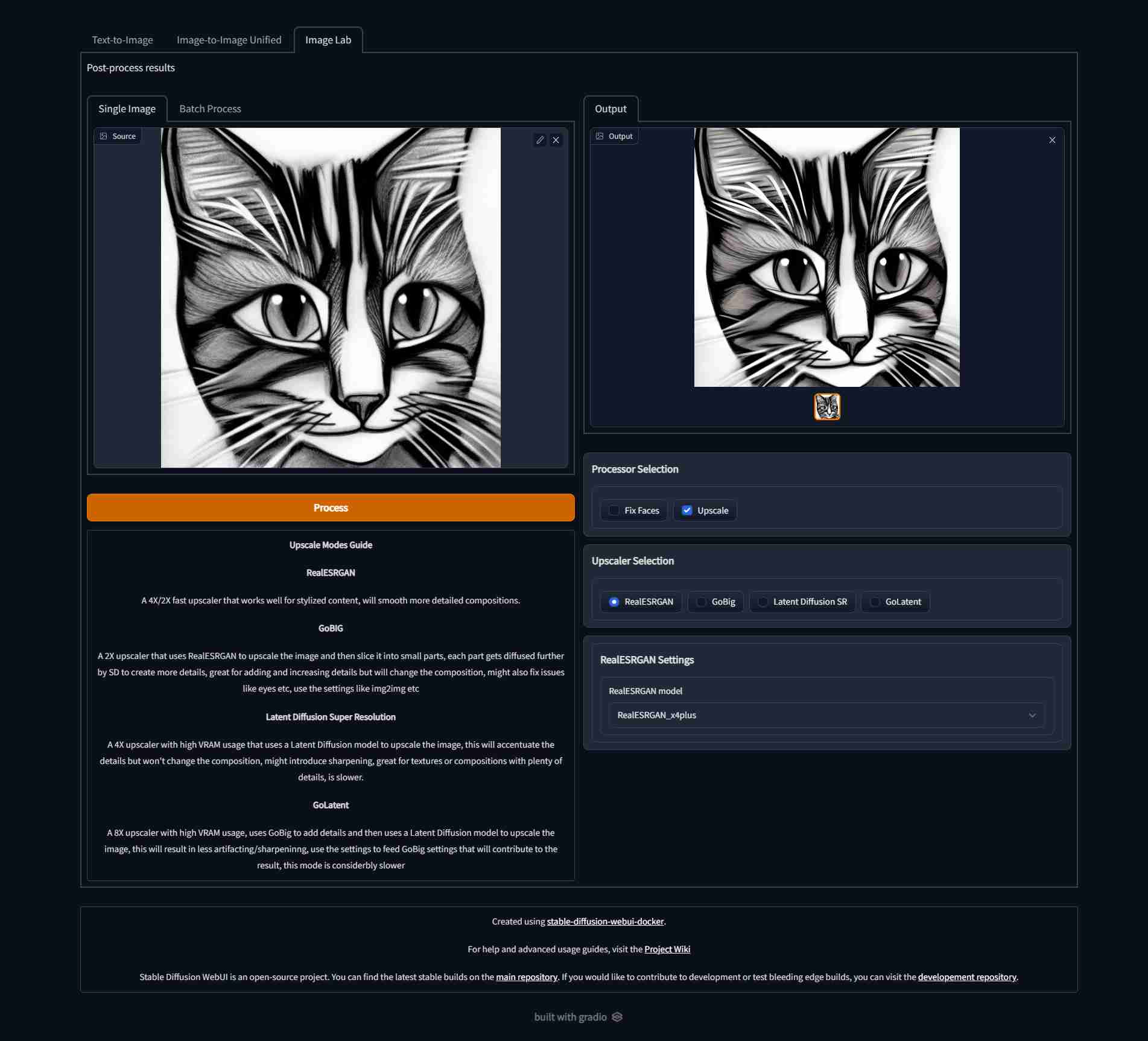 |
|
||||
|
||||
After the build is done, you can run the app with:
|
||||
### lstein
|
||||
|
||||
```
|
||||
docker compose up --build
|
||||
```
|
||||
[lstein's fork](https://github.com/lstein/stable-diffusion) is very mature when it comes to the cli, but less so for the WebUI.
|
||||
|
||||
Will start the app on http://localhost:7860/
|
||||
## Setup & Usage
|
||||
|
||||
Note: the first start will take sometime as some other models will be downloaded, these will be cached in the `cache` folder, so next runs are faster.
|
||||
Visit the wiki for [Setup](https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/Setup) and [Usage](https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/Usage) instructions, checkout the [FAQ](https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/FAQ) page if you face any problems, or create a new issue!
|
||||
|
||||
### FAQ
|
||||
|
||||
You can find fixes to common issues [in the wiki page.](https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/FAQ)
|
||||
|
||||
## Config
|
||||
|
||||
in the `docker-compose.yml` you can change the `CLI_ARGS` variable, which contains the arguments that will be passed to the WebUI. By default: `--extra-models-cpu --optimized-turbo` are given, which allow you to use this model on a 6GB GPU. However, some features might not be available in the mode. [You can find the full list of arguments here.](https://github.com/hlky/stable-diffusion-webui/blob/2b1ac8daf7ea82c6c56eabab7e80ec1c33106a98/scripts/webui.py)
|
||||
|
||||
You can set the `WEBUI_SHA` to [any SHA from the main repo](https://github.com/hlky/stable-diffusion/commits/main), this will build the container against that commit. Use at your own risk.
|
||||
|
||||
# Disclaimer
|
||||
## Disclaimer
|
||||
|
||||
The authors of this project are not responsible for any content generated using this interface.
|
||||
|
||||
This license of this software forbids you from sharing any content that violates any laws, produce any harm to a person, disseminate any personal information that would be meant for harm, spread misinformation and target vulnerable groups. For the full list of restrictions please read [the license](./LICENSE).
|
||||
|
||||
# Thanks
|
||||
## Thanks
|
||||
|
||||
Special thanks to everyone behind these awesome projects, without them, none of this would have been possible:
|
||||
|
||||
@@ -89,3 +63,4 @@ Special thanks to everyone behind these awesome projects, without them, none of
|
||||
- [CompVis/stable-diffusion](https://github.com/CompVis/stable-diffusion)
|
||||
- [hlky/sd-enable-textual-inversion](https://github.com/hlky/sd-enable-textual-inversion)
|
||||
- [devilismyfriend/latent-diffusion](https://github.com/devilismyfriend/latent-diffusion)
|
||||
- [Hafiidz/latent-diffusion](https://github.com/Hafiidz/latent-diffusion)
|
||||
|
||||
3
cache/.gitignore
vendored
3
cache/.gitignore
vendored
@@ -1,3 +1,4 @@
|
||||
/torch
|
||||
/transformers
|
||||
/weights
|
||||
/weights
|
||||
/models
|
||||
|
||||
@@ -1,21 +1,11 @@
|
||||
version: '3.9'
|
||||
|
||||
services:
|
||||
model:
|
||||
build:
|
||||
context: ./hlky/
|
||||
args:
|
||||
# You can choose any commit sha from https://github.com/hlky/stable-diffusion/commits/main
|
||||
# USE AT YOUR OWN RISK! otherwise just leave it empty.
|
||||
WEBUI_SHA:
|
||||
x-base_service: &base_service
|
||||
ports:
|
||||
- "7860:7860"
|
||||
volumes:
|
||||
- ./cache:/cache
|
||||
- ./output:/output
|
||||
- ./models:/models
|
||||
environment:
|
||||
- CLI_ARGS=--extra-models-cpu --optimized-turbo
|
||||
- &v1 ./cache:/cache
|
||||
- &v2 ./output:/output
|
||||
deploy:
|
||||
resources:
|
||||
reservations:
|
||||
@@ -23,3 +13,42 @@ services:
|
||||
- driver: nvidia
|
||||
device_ids: ['0']
|
||||
capabilities: [gpu]
|
||||
|
||||
name: webui-docker
|
||||
|
||||
services:
|
||||
download:
|
||||
build: ./services/download/
|
||||
profiles: ["download"]
|
||||
volumes:
|
||||
- *v1
|
||||
|
||||
hlky:
|
||||
<<: *base_service
|
||||
profiles: ["hlky"]
|
||||
build: ./services/hlky/
|
||||
environment:
|
||||
- CLI_ARGS=--optimized-turbo
|
||||
|
||||
automatic1111: &automatic
|
||||
<<: *base_service
|
||||
profiles: ["auto"]
|
||||
build: ./services/AUTOMATIC1111
|
||||
volumes:
|
||||
- *v1
|
||||
- *v2
|
||||
- ./services/AUTOMATIC1111/config.json:/stable-diffusion-webui/config.json
|
||||
environment:
|
||||
- CLI_ARGS=--medvram --opt-split-attention
|
||||
|
||||
automatic1111-cpu:
|
||||
<<: *automatic
|
||||
profiles: ["auto-cpu"]
|
||||
deploy: {}
|
||||
environment:
|
||||
- CLI_ARGS=--no-half --precision full
|
||||
|
||||
lstein:
|
||||
<<: *base_service
|
||||
profiles: ["lstein"]
|
||||
build: ./services/lstein/
|
||||
|
||||
@@ -1,20 +0,0 @@
|
||||
version: '3.9'
|
||||
|
||||
services:
|
||||
model:
|
||||
build: .
|
||||
ports:
|
||||
- "7860:7860"
|
||||
volumes:
|
||||
- ../cache:/cache
|
||||
- ../output:/output
|
||||
- ../models:/models
|
||||
environment:
|
||||
- CLI_ARGS=
|
||||
deploy:
|
||||
resources:
|
||||
reservations:
|
||||
devices:
|
||||
- driver: nvidia
|
||||
device_ids: ['0']
|
||||
capabilities: [gpu]
|
||||
7
models/.gitignore
vendored
7
models/.gitignore
vendored
@@ -1,7 +0,0 @@
|
||||
/model.ckpt
|
||||
/GFPGANv1.3.pth
|
||||
/RealESRGAN_x2plus.pth
|
||||
/RealESRGAN_x4plus.pth
|
||||
/RealESRGAN_x4plus_anime_6B.pth
|
||||
/LDSR.ckpt
|
||||
/LDSR.yaml
|
||||
5
scripts/chmod.sh
Executable file
5
scripts/chmod.sh
Executable file
@@ -0,0 +1,5 @@
|
||||
#!/bin/bash
|
||||
|
||||
set -Eeuo pipefail
|
||||
|
||||
find . -name "*.sh" -exec git update-index --chmod=+x {} \;
|
||||
@@ -2,52 +2,62 @@
|
||||
|
||||
FROM alpine/git:2.36.2 as download
|
||||
RUN <<EOF
|
||||
# who knows
|
||||
# because taming-transformers is huge
|
||||
git config --global http.postBuffer 1048576000
|
||||
git clone https://github.com/sczhou/CodeFormer.git repositories/CodeFormer
|
||||
git clone https://github.com/CompVis/stable-diffusion.git repositories/stable-diffusion
|
||||
git clone https://github.com/salesforce/BLIP.git repositories/BLIP
|
||||
git clone https://github.com/CompVis/taming-transformers.git repositories/taming-transformers
|
||||
rm -rf repositories/taming-transformers/data repositories/taming-transformers/assets
|
||||
EOF
|
||||
|
||||
FROM pytorch/pytorch:1.12.1-cuda11.3-cudnn8-runtime
|
||||
|
||||
FROM continuumio/miniconda3:4.12.0
|
||||
|
||||
SHELL ["/bin/bash", "-ceuxo", "pipefail"]
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
RUN apt-get update && apt-get install git fonts-dejavu-core -y && apt-get clean
|
||||
|
||||
RUN conda install python=3.8.5 && conda clean -a -y
|
||||
RUN conda install pytorch==1.11.0 torchvision==0.12.0 cudatoolkit=11.3 -c pytorch && conda clean -a -y
|
||||
|
||||
RUN apt-get update && apt install fonts-dejavu-core rsync -y && apt-get clean
|
||||
|
||||
|
||||
RUN <<EOF
|
||||
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
|
||||
cd stable-diffusion-webui
|
||||
git reset --hard db6db585eb9ee48e7315e28603e18531dbc87067
|
||||
pip install -U --prefer-binary --no-cache-dir -r requirements.txt
|
||||
git reset --hard 13eec4f3d4081fdc43883c5ef02e471a2b6c7212
|
||||
conda env update --file environment-wsl2.yaml -n base
|
||||
conda clean -a -y
|
||||
pip install --prefer-binary --no-cache-dir -r requirements.txt
|
||||
EOF
|
||||
|
||||
ENV ROOT=/workspace/stable-diffusion-webui \
|
||||
WORKDIR=/workspace/stable-diffusion-webui/repositories/stable-diffusion
|
||||
ENV ROOT=/stable-diffusion-webui \
|
||||
WORKDIR=/stable-diffusion-webui/repositories/stable-diffusion
|
||||
|
||||
COPY --from=download /git/ ${ROOT}
|
||||
RUN pip install --prefer-binary -U --no-cache-dir -r ${ROOT}/repositories/CodeFormer/requirements.txt
|
||||
RUN pip install --prefer-binary --no-cache-dir -r ${ROOT}/repositories/CodeFormer/requirements.txt
|
||||
|
||||
# Note: don't update the sha of previous versions because the install will take forever
|
||||
# instead, update the repo state in a later step
|
||||
ARG SHA=701f76b29ab8fa9c1d35ae8abce36b99e12d5d08
|
||||
ARG SHA=744ac1f89a075be4535146279feef800214c35a8
|
||||
RUN <<EOF
|
||||
cd stable-diffusion-webui
|
||||
git pull
|
||||
git pull --rebase
|
||||
git reset --hard ${SHA}
|
||||
pip install --prefer-binary --no-cache-dir -r requirements.txt
|
||||
EOF
|
||||
|
||||
RUN pip install --prefer-binary -U --no-cache-dir opencv-python-headless markupsafe==2.0.1
|
||||
RUN pip install --prefer-binary -U --no-cache-dir opencv-python-headless markupsafe==2.0.1 gfpgan==1.3.5
|
||||
|
||||
ENV TRANSFORMERS_CACHE=/cache/transformers TORCH_HOME=/cache/torch CLI_ARGS=""
|
||||
|
||||
COPY . /docker
|
||||
RUN chmod +x /docker/mount.sh && python3 /docker/info.py ${ROOT}/modules/ui.py
|
||||
|
||||
|
||||
WORKDIR ${WORKDIR}
|
||||
EXPOSE 7860
|
||||
# run, -u to not buffer stdout / stderr
|
||||
CMD /docker/mount.sh && python3 -u ../../webui.py --listen --port 7860 ${CLI_ARGS}
|
||||
CMD /docker/mount.sh && python3 -u ../../webui.py --listen --port 7860 --hide-ui-dir-config ${CLI_ARGS}
|
||||
48
services/AUTOMATIC1111/config.json
Normal file
48
services/AUTOMATIC1111/config.json
Normal file
@@ -0,0 +1,48 @@
|
||||
{
|
||||
"outdir_samples": "/output",
|
||||
"outdir_txt2img_samples": "/output/txt2img-images",
|
||||
"outdir_img2img_samples": "/output/img2img-images",
|
||||
"outdir_extras_samples": "/output/extras-images",
|
||||
"outdir_txt2img_grids": "/output/txt2img-grids",
|
||||
"outdir_img2img_grids": "/output/img2img-grids",
|
||||
"outdir_save": "/output/saved",
|
||||
"font": "DejaVuSans.ttf",
|
||||
"__WARNING__": "DON'T CHANGE ANYTHING BEFORE THIS",
|
||||
|
||||
"samples_filename_format": "",
|
||||
"outdir_grids": "",
|
||||
"save_to_dirs": false,
|
||||
"grid_save_to_dirs": false,
|
||||
"save_to_dirs_prompt_len": 10,
|
||||
"samples_save": true,
|
||||
"samples_format": "png",
|
||||
"grid_save": true,
|
||||
"return_grid": true,
|
||||
"grid_format": "png",
|
||||
"grid_extended_filename": false,
|
||||
"grid_only_if_multiple": true,
|
||||
"n_rows": -1,
|
||||
"jpeg_quality": 80,
|
||||
"export_for_4chan": true,
|
||||
"enable_pnginfo": true,
|
||||
"add_model_hash_to_info": false,
|
||||
"enable_emphasis": true,
|
||||
"save_txt": false,
|
||||
"ESRGAN_tile": 192,
|
||||
"ESRGAN_tile_overlap": 8,
|
||||
"random_artist_categories": [],
|
||||
"upscale_at_full_resolution_padding": 16,
|
||||
"show_progressbar": true,
|
||||
"show_progress_every_n_steps": 7,
|
||||
"multiple_tqdm": true,
|
||||
"face_restoration_model": null,
|
||||
"code_former_weight": 0.5,
|
||||
"save_images_before_face_restoration": false,
|
||||
"face_restoration_unload": false,
|
||||
"interrogate_keep_models_in_memory": false,
|
||||
"interrogate_use_builtin_artists": true,
|
||||
"interrogate_clip_num_beams": 1,
|
||||
"interrogate_clip_min_length": 24,
|
||||
"interrogate_clip_max_length": 48,
|
||||
"interrogate_clip_dict_limit": 1500.0
|
||||
}
|
||||
@@ -1,14 +1,18 @@
|
||||
#!/bin/bash
|
||||
|
||||
set -e
|
||||
|
||||
declare -A MODELS
|
||||
|
||||
MODELS["${WORKDIR}/models/ldm/stable-diffusion-v1/model.ckpt"]=model.ckpt
|
||||
MODELS["${ROOT}/GFPGANv1.3.pth"]=GFPGANv1.3.pth
|
||||
|
||||
MODELS_DIR=/cache/models
|
||||
|
||||
for path in "${!MODELS[@]}"; do
|
||||
name=${MODELS[$path]}
|
||||
base=$(dirname "${path}")
|
||||
from_path="/models/${name}"
|
||||
from_path="${MODELS_DIR}/${name}"
|
||||
if test -f "${from_path}"; then
|
||||
mkdir -p "${base}" && ln -sf "${from_path}" "${path}" && echo "Mounted ${name}"
|
||||
else
|
||||
@@ -17,8 +21,8 @@ for path in "${!MODELS[@]}"; do
|
||||
done
|
||||
|
||||
# force realesrgan cache
|
||||
rm -rf /opt/conda/lib/python3.7/site-packages/realesrgan/weights
|
||||
ln -s -T /models /opt/conda/lib/python3.7/site-packages/realesrgan/weights
|
||||
rm -rf /opt/conda/lib/python3.8/site-packages/realesrgan/weights
|
||||
ln -s -T "${MODELS_DIR}" /opt/conda/lib/python3.8/site-packages/realesrgan/weights
|
||||
|
||||
# force facexlib cache
|
||||
mkdir -p /cache/weights/ ${WORKDIR}/gfpgan/
|
||||
@@ -29,4 +33,4 @@ ln -sf -T /cache/weights ${ROOT}/repositories/CodeFormer/weights/CodeFormer
|
||||
ln -sf -T /cache/weights ${ROOT}/repositories/CodeFormer/weights/facelib
|
||||
|
||||
# mount config
|
||||
ln -sf /docker/config.json ${WORKDIR}/config.json
|
||||
# ln -sf /docker/config.json ${WORKDIR}/config.json
|
||||
6
services/download/Dockerfile
Normal file
6
services/download/Dockerfile
Normal file
@@ -0,0 +1,6 @@
|
||||
FROM bash:alpine3.15
|
||||
|
||||
RUN apk add parallel
|
||||
COPY . /docker
|
||||
RUN chmod +x /docker/download.sh
|
||||
ENTRYPOINT ["/docker/download.sh"]
|
||||
6
services/download/checksums.sha256
Normal file
6
services/download/checksums.sha256
Normal file
@@ -0,0 +1,6 @@
|
||||
fe4efff1e174c627256e44ec2991ba279b3816e364b49f9be2abc0b3ff3f8556 /cache/models/model.ckpt
|
||||
c953a88f2727c85c3d9ae72e2bd4846bbaf59fe6972ad94130e23e7017524a70 /cache/models/GFPGANv1.3.pth
|
||||
4fa0d38905f75ac06eb49a7951b426670021be3018265fd191d2125df9d682f1 /cache/models/RealESRGAN_x4plus.pth
|
||||
f872d837d3c90ed2e05227bed711af5671a6fd1c9f7d7e91c911a61f155e99da /cache/models/RealESRGAN_x4plus_anime_6B.pth
|
||||
c209caecac2f97b4bb8f4d726b70ac2ac9b35904b7fc99801e1f5e61f9210c13 /cache/models/LDSR.ckpt
|
||||
9d6ad53c5dafeb07200fb712db14b813b527edd262bc80ea136777bdb41be2ba /cache/models/LDSR.yaml
|
||||
33
services/download/download.sh
Executable file
33
services/download/download.sh
Executable file
@@ -0,0 +1,33 @@
|
||||
#!/usr/bin/env bash
|
||||
|
||||
set -Eeuo pipefail
|
||||
|
||||
# [[ "$(sha256sum -b $file | head -c 64)" == "$sha" ]]
|
||||
|
||||
declare -A MODELS
|
||||
|
||||
MODELS['model.ckpt']='https://www.googleapis.com/storage/v1/b/aai-blog-files/o/sd-v1-4.ckpt?alt=media'
|
||||
MODELS['GFPGANv1.3.pth']='https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.3.pth'
|
||||
MODELS['RealESRGAN_x4plus.pth']='https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth'
|
||||
MODELS['RealESRGAN_x4plus_anime_6B.pth']='https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.2.4/RealESRGAN_x4plus_anime_6B.pth'
|
||||
MODELS['LDSR.yaml']='https://heibox.uni-heidelberg.de/f/31a76b13ea27482981b4/?dl=1'
|
||||
MODELS['LDSR.ckpt']='https://heibox.uni-heidelberg.de/f/578df07c8fc04ffbadf3/?dl=1'
|
||||
|
||||
echo "Downloading..."
|
||||
|
||||
for file in "${!MODELS[@]}"; do
|
||||
url=${MODELS[$file]}
|
||||
full_path="/cache/models/$file"
|
||||
|
||||
if [[ -f "$full_path" ]]; then
|
||||
echo "- $file exists"
|
||||
continue
|
||||
fi
|
||||
|
||||
mkdir -p $(dirname $full_path)
|
||||
wget --tries=10 -c -O $full_path $url
|
||||
done
|
||||
|
||||
echo "Checking SHAs..."
|
||||
|
||||
time parallel --will-cite -a /docker/checksums.sha256 "echo -n {} | sha256sum -c"
|
||||
@@ -4,6 +4,8 @@ FROM continuumio/miniconda3:4.12.0
|
||||
|
||||
SHELL ["/bin/bash", "-ceuxo", "pipefail"]
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
RUN conda install python=3.8.5 && conda clean -a -y
|
||||
RUN conda install pytorch==1.11.0 torchvision==0.12.0 cudatoolkit=11.3 -c pytorch && conda clean -a -y
|
||||
|
||||
@@ -13,7 +15,7 @@ RUN apt-get update && apt install fonts-dejavu-core rsync -y && apt-get clean
|
||||
RUN <<EOF
|
||||
git clone https://github.com/sd-webui/stable-diffusion-webui.git stable-diffusion
|
||||
cd stable-diffusion
|
||||
git reset --hard 2b1ac8daf7ea82c6c56eabab7e80ec1c33106a98
|
||||
git reset --hard 7623a5734740025d79b710f3744bff9276e1467b
|
||||
conda env update --file environment.yaml -n base
|
||||
conda clean -a -y
|
||||
EOF
|
||||
@@ -23,23 +25,22 @@ RUN pip install -U --no-cache-dir pyperclip
|
||||
|
||||
# Note: don't update the sha of previous versions because the install will take forever
|
||||
# instead, update the repo state in a later step
|
||||
ARG WEBUI_SHA=0dffc3918d596ad36a32ac56ecf4d523f490ae5e
|
||||
RUN cd stable-diffusion && git pull && git reset --hard ${WEBUI_SHA} && \
|
||||
conda env update --file environment.yaml --name base && conda clean -a -y
|
||||
|
||||
# Textual inversion
|
||||
ARG BRANCH=master
|
||||
ARG SHA=7623a5734740025d79b710f3744bff9276e1467b
|
||||
RUN <<EOF
|
||||
git clone https://github.com/hlky/sd-enable-textual-inversion.git &&
|
||||
cd /sd-enable-textual-inversion && git reset --hard 08f9b5046552d17cf7327b30a98410222741b070 &&
|
||||
rsync -a /sd-enable-textual-inversion/ /stable-diffusion/ &&
|
||||
rm -rf /sd-enable-textual-inversion
|
||||
cd stable-diffusion
|
||||
git fetch
|
||||
git checkout ${BRANCH}
|
||||
git reset --hard ${SHA}
|
||||
conda env update --file environment.yaml -n base
|
||||
conda clean -a -y
|
||||
EOF
|
||||
|
||||
# Latent diffusion
|
||||
RUN <<EOF
|
||||
git clone https://github.com/devilismyfriend/latent-diffusion &&
|
||||
cd /latent-diffusion &&
|
||||
git reset --hard 6d61fc03f15273a457950f2cdc10dddf53ba6809 &&
|
||||
git clone https://github.com/Hafiidz/latent-diffusion.git
|
||||
cd latent-diffusion
|
||||
git reset --hard e1a84a89fcbb49881546cf2acf1e7e250923dba0
|
||||
# hacks all the way down
|
||||
mv ldm ldm_latent &&
|
||||
sed -i -- 's/from ldm/from ldm_latent/g' *.py
|
||||
@@ -55,4 +56,4 @@ WORKDIR /stable-diffusion
|
||||
ENV TRANSFORMERS_CACHE=/cache/transformers TORCH_HOME=/cache/torch CLI_ARGS=""
|
||||
EXPOSE 7860
|
||||
# run, -u to not buffer stdout / stderr
|
||||
CMD /docker/mount.sh && python3 -u scripts/webui.py --outdir /output --ckpt /models/model.ckpt --ldsr-dir /latent-diffusion ${CLI_ARGS}
|
||||
CMD /docker/mount.sh && python3 -u scripts/webui.py --outdir /output --ckpt /cache/models/model.ckpt --ldsr-dir /latent-diffusion ${CLI_ARGS}
|
||||
@@ -3,16 +3,21 @@
|
||||
set -e
|
||||
|
||||
declare -A MODELS
|
||||
MODELS["/stable-diffusion/src/gfpgan/experiments/pretrained_models/GFPGANv1.3.pth"]=GFPGANv1.3.pth
|
||||
MODELS["/stable-diffusion/src/realesrgan/experiments/pretrained_models/RealESRGAN_x4plus.pth"]=RealESRGAN_x4plus.pth
|
||||
MODELS["/stable-diffusion/src/realesrgan/experiments/pretrained_models/RealESRGAN_x4plus_anime_6B.pth"]=RealESRGAN_x4plus_anime_6B.pth
|
||||
|
||||
ROOT=/stable-diffusion/src
|
||||
|
||||
MODELS["${ROOT}/gfpgan/experiments/pretrained_models/GFPGANv1.3.pth"]=GFPGANv1.3.pth
|
||||
MODELS["${ROOT}/realesrgan/experiments/pretrained_models/RealESRGAN_x4plus.pth"]=RealESRGAN_x4plus.pth
|
||||
MODELS["${ROOT}/realesrgan/experiments/pretrained_models/RealESRGAN_x4plus_anime_6B.pth"]=RealESRGAN_x4plus_anime_6B.pth
|
||||
MODELS["/latent-diffusion/experiments/pretrained_models/model.ckpt"]=LDSR.ckpt
|
||||
# MODELS["/latent-diffusion/experiments/pretrained_models/project.yaml"]=LDSR.yaml
|
||||
|
||||
MODELS_DIR=/cache/models
|
||||
|
||||
for path in "${!MODELS[@]}"; do
|
||||
name=${MODELS[$path]}
|
||||
base=$(dirname "${path}")
|
||||
from_path="/models/${name}"
|
||||
from_path="${MODELS_DIR}/${name}"
|
||||
if test -f "${from_path}"; then
|
||||
mkdir -p "${base}" && ln -sf "${from_path}" "${path}" && echo "Mounted ${name}"
|
||||
else
|
||||
@@ -21,8 +26,8 @@ for path in "${!MODELS[@]}"; do
|
||||
done
|
||||
|
||||
# hack for latent-diffusion
|
||||
if test -f /models/LDSR.yaml; then
|
||||
sed 's/ldm\./ldm_latent\./g' /models/LDSR.yaml >/latent-diffusion/experiments/pretrained_models/project.yaml
|
||||
if test -f "${MODELS_DIR}/LDSR.yaml"; then
|
||||
sed 's/ldm\./ldm_latent\./g' "${MODELS_DIR}/LDSR.yaml" >/latent-diffusion/experiments/pretrained_models/project.yaml
|
||||
fi
|
||||
|
||||
# force facexlib cache
|
||||
@@ -4,6 +4,8 @@ FROM continuumio/miniconda3:4.12.0
|
||||
|
||||
SHELL ["/bin/bash", "-ceuxo", "pipefail"]
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
RUN conda install python=3.8.5 && conda clean -a -y
|
||||
RUN conda install pytorch==1.11.0 torchvision==0.12.0 cudatoolkit=11.3 -c pytorch && conda clean -a -y
|
||||
|
||||
@@ -25,5 +27,5 @@ WORKDIR /stable-diffusion
|
||||
EXPOSE 7860
|
||||
# run, -u to not buffer stdout / stderr
|
||||
CMD mkdir -p /stable-diffusion/models/ldm/stable-diffusion-v1/ && \
|
||||
ln -sf /models/model.ckpt /stable-diffusion/models/ldm/stable-diffusion-v1/model.ckpt && \
|
||||
ln -sf /cache/models/model.ckpt /stable-diffusion/models/ldm/stable-diffusion-v1/model.ckpt && \
|
||||
python3 -u scripts/dream.py --outdir /output --web --host 0.0.0.0 --port 7860 ${CLI_ARGS}
|
||||
Reference in New Issue
Block a user