mirror of
https://github.com/AbdBarho/stable-diffusion-webui-docker.git
synced 2025-10-27 08:14:26 -04:00
Compare commits
40 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
43a5e5e85f | ||
|
|
5bbc21ea3d | ||
|
|
09366ed955 | ||
|
|
d4874e7c3a | ||
|
|
7638fb4e5e | ||
|
|
15a61a99d6 | ||
|
|
556a50f49b | ||
|
|
b899f4e516 | ||
|
|
a8c85b4699 | ||
|
|
a96285d10b | ||
|
|
83b78fe504 | ||
|
|
84f9cb84e7 | ||
|
|
6a66ff6abb | ||
|
|
59892da866 | ||
|
|
fceb83c2b0 | ||
|
|
17b01a7627 | ||
|
|
b96d7c30d0 | ||
|
|
aae83bb8f2 | ||
|
|
10763a8f61 | ||
|
|
64e8f093d2 | ||
|
|
3e0a137c23 | ||
|
|
a1c16942ff | ||
|
|
6ae3473214 | ||
|
|
5d731cb43c | ||
|
|
c1fa2f1457 | ||
|
|
d8cfdd3af5 | ||
|
|
03d12cbcd9 | ||
|
|
2e76b6c4e7 | ||
|
|
5eae2076ce | ||
|
|
725e1f39ba | ||
|
|
ab651fe0d7 | ||
|
|
f76f8d4671 | ||
|
|
e32a48f42a | ||
|
|
76989b39a6 | ||
|
|
4d9fc381bb | ||
|
|
bcee253fe0 | ||
|
|
499143009a | ||
|
|
c614625f04 | ||
|
|
ccd6e238b2 | ||
|
|
829864af9b |
11
.github/ISSUE_TEMPLATE/bug.md
vendored
11
.github/ISSUE_TEMPLATE/bug.md
vendored
@@ -7,13 +7,17 @@ assignees: ''
|
||||
|
||||
---
|
||||
|
||||
**Has this issue been opened before? Check the [FAQ](https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/Main), the [issues](https://github.com/AbdBarho/stable-diffusion-webui-docker/issues?q=is%3Aissue) and in [the issues in the WebUI repo](https://github.com/hlky/stable-diffusion-webui)**
|
||||
**Has this issue been opened before? Check the [FAQ](https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/Main), the [issues](https://github.com/AbdBarho/stable-diffusion-webui-docker/issues?q=is%3Aissue)**
|
||||
|
||||
|
||||
|
||||
**Describe the bug**
|
||||
|
||||
|
||||
**Which UI**
|
||||
|
||||
hlky or auto or auto-cpu or lstein?
|
||||
|
||||
**Steps to Reproduce**
|
||||
1. Go to '...'
|
||||
2. Click on '....'
|
||||
@@ -22,8 +26,11 @@ assignees: ''
|
||||
|
||||
**Hardware / Software:**
|
||||
- OS: [e.g. Windows / Ubuntu and version]
|
||||
- RAM:
|
||||
- GPU: [Nvidia 1660 / No GPU]
|
||||
- Version [e.g. 22]
|
||||
- VRAM:
|
||||
- Docker Version, Docker compose version
|
||||
- Release version [e.g. 1.0.1]
|
||||
|
||||
**Additional context**
|
||||
Any other context about the problem here. If applicable, add screenshots to help explain your problem.
|
||||
|
||||
5
.github/pull_request_template.md
vendored
Normal file
5
.github/pull_request_template.md
vendored
Normal file
@@ -0,0 +1,5 @@
|
||||
### Update versions
|
||||
|
||||
- auto: https://github.com/AUTOMATIC1111/stable-diffusion-webui/commit/
|
||||
- hlky: https://github.com/sd-webui/stable-diffusion-webui/commit/
|
||||
- lstein: https://github.com/lstein/stable-diffusion/commit/
|
||||
29
.github/workflows/docker.yml
vendored
29
.github/workflows/docker.yml
vendored
@@ -1,24 +1,19 @@
|
||||
name: Build Image
|
||||
name: Build Images
|
||||
|
||||
on: [push]
|
||||
|
||||
# TODO: how to cache intermediate images?
|
||||
jobs:
|
||||
build_hlky:
|
||||
build:
|
||||
strategy:
|
||||
matrix:
|
||||
profile:
|
||||
- auto
|
||||
- hlky
|
||||
- lstein
|
||||
- download
|
||||
runs-on: ubuntu-latest
|
||||
name: Build hlky
|
||||
name: ${{ matrix.profile }}
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- run: docker compose build --progress plain
|
||||
build_AUTOMATIC1111:
|
||||
runs-on: ubuntu-latest
|
||||
name: Build AUTOMATIC1111
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- run: cd AUTOMATIC1111 && docker compose build --progress plain
|
||||
build_lstein:
|
||||
runs-on: ubuntu-latest
|
||||
name: Build lstein
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- run: cd lstein && docker compose build --progress plain
|
||||
# better caching?
|
||||
- run: docker compose --profile ${{ matrix.profile }} build --progress plain
|
||||
|
||||
22
.github/workflows/executable.yml1
vendored
Normal file
22
.github/workflows/executable.yml1
vendored
Normal file
@@ -0,0 +1,22 @@
|
||||
name: Check executable
|
||||
|
||||
on: [push]
|
||||
|
||||
jobs:
|
||||
check:
|
||||
runs-on: ubuntu-latest
|
||||
name: Check all sh
|
||||
steps:
|
||||
- run: git config --global core.fileMode true
|
||||
- uses: actions/checkout@v3
|
||||
- shell: bash
|
||||
run: |
|
||||
shopt -s globstar;
|
||||
FAIL=0
|
||||
for file in **/*.sh; do
|
||||
if [ -f "${file}" ] && [ -r "${file}" ] && [ ! -x "${file}" ]; then
|
||||
echo "$file" is not executable;
|
||||
FAIL=1
|
||||
fi
|
||||
done
|
||||
exit ${FAIL}
|
||||
21
.github/workflows/stale.yml
vendored
Normal file
21
.github/workflows/stale.yml
vendored
Normal file
@@ -0,0 +1,21 @@
|
||||
name: 'Close stale issues and PRs'
|
||||
on:
|
||||
schedule:
|
||||
- cron: '30 1 * * *'
|
||||
|
||||
jobs:
|
||||
stale:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/stale@v5
|
||||
with:
|
||||
only-labels: awaiting-response
|
||||
stale-issue-message: This issue is stale because it has been open 14 days with no activity. Remove stale label or comment or this will be closed in 7 days.
|
||||
stale-pr-message: This PR is stale because it has been open 14 days with no activity. Remove stale label or comment or this will be closed in 7 days.
|
||||
close-issue-message: This issue was closed because it has been stalled for 7 days with no activity.
|
||||
close-pr-message: This PR was closed because it has been stalled for 7 days with no activity.
|
||||
days-before-issue-stale: 14
|
||||
days-before-pr-stale: 14
|
||||
days-before-issue-close: 7
|
||||
days-before-pr-close: 7
|
||||
ignore-updates: true
|
||||
1
.gitignore
vendored
1
.gitignore
vendored
@@ -1,2 +1,3 @@
|
||||
/dev
|
||||
/.devcontainer
|
||||
embeddings/*
|
||||
@@ -1,44 +0,0 @@
|
||||
# syntax=docker/dockerfile:1
|
||||
|
||||
FROM alpine/git:2.36.2 as download
|
||||
RUN <<EOF
|
||||
# who knows
|
||||
git config --global http.postBuffer 1048576000
|
||||
git clone https://github.com/CompVis/stable-diffusion.git repositories/stable-diffusion
|
||||
git clone https://github.com/CompVis/taming-transformers.git repositories/taming-transformers
|
||||
rm -rf repositories/taming-transformers/data repositories/taming-transformers/assets
|
||||
EOF
|
||||
|
||||
FROM pytorch/pytorch:1.12.1-cuda11.3-cudnn8-runtime
|
||||
|
||||
SHELL ["/bin/bash", "-ceuxo", "pipefail"]
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
RUN apt-get update && apt-get install git -y && apt-get clean
|
||||
|
||||
RUN <<EOF
|
||||
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
|
||||
cd stable-diffusion-webui
|
||||
git reset --hard 064965c4660f57f24e2d51a9854defaeabf8c0cf
|
||||
pip install -U --prefer-binary --no-cache-dir -r requirements.txt
|
||||
EOF
|
||||
|
||||
RUN <<EOF
|
||||
pip install --prefer-binary -U --no-cache-dir diffusers numpy invisible-watermark git+https://github.com/crowsonkb/k-diffusion.git \
|
||||
git+https://github.com/TencentARC/GFPGAN.git markupsafe==2.0.1 opencv-python-headless
|
||||
EOF
|
||||
|
||||
|
||||
ENV ROOT=/workspace/stable-diffusion-webui \
|
||||
WORKDIR=/workspace/stable-diffusion-webui/repositories/stable-diffusion \
|
||||
TRANSFORMERS_CACHE=/cache/transformers TORCH_HOME=/cache/torch CLI_ARGS=""
|
||||
|
||||
COPY --from=download /git/ ${ROOT}
|
||||
|
||||
|
||||
COPY . /docker
|
||||
|
||||
WORKDIR ${WORKDIR}
|
||||
EXPOSE 7860
|
||||
# run, -u to not buffer stdout / stderr
|
||||
CMD /docker/mount.sh && python3 -u ../../webui.py --listen ${CLI_ARGS}
|
||||
@@ -1,12 +0,0 @@
|
||||
# WebUI for AUTOMATIC1111
|
||||
|
||||
The WebUI of [AUTOMATIC1111/stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui) as docker container!
|
||||
|
||||
## Setup
|
||||
|
||||
Clone this repo, download the `model.ckpt` and `GFPGANv1.3.pth` and put into the `models` folder as mentioned in [the main README](../README.md), then run
|
||||
|
||||
```
|
||||
cd AUTOMATIC1111
|
||||
docker compose up --build
|
||||
```
|
||||
@@ -1,3 +0,0 @@
|
||||
{
|
||||
"outdir_samples": "/output"
|
||||
}
|
||||
@@ -1,20 +0,0 @@
|
||||
version: '3.9'
|
||||
|
||||
services:
|
||||
model:
|
||||
build: .
|
||||
ports:
|
||||
- "7860:7860"
|
||||
volumes:
|
||||
- ../cache:/cache
|
||||
- ../output:/output
|
||||
- ../models:/models
|
||||
environment:
|
||||
- CLI_ARGS=--medvram --opt-split-attention
|
||||
deploy:
|
||||
resources:
|
||||
reservations:
|
||||
devices:
|
||||
- driver: nvidia
|
||||
device_ids: ['0']
|
||||
capabilities: [gpu]
|
||||
@@ -1,28 +0,0 @@
|
||||
#!/bin/bash
|
||||
|
||||
declare -A MODELS
|
||||
|
||||
MODELS["${WORKDIR}/models/ldm/stable-diffusion-v1/model.ckpt"]=model.ckpt
|
||||
MODELS["${ROOT}/GFPGANv1.3.pth"]=GFPGANv1.3.pth
|
||||
|
||||
for path in "${!MODELS[@]}"; do
|
||||
name=${MODELS[$path]}
|
||||
base=$(dirname "${path}")
|
||||
from_path="/models/${name}"
|
||||
if test -f "${from_path}"; then
|
||||
mkdir -p "${base}" && ln -sf "${from_path}" "${path}" && echo "Mounted ${name}"
|
||||
else
|
||||
echo "Skipping ${name}"
|
||||
fi
|
||||
done
|
||||
|
||||
# force realesrgan cache
|
||||
rm -rf /opt/conda/lib/python3.7/site-packages/realesrgan/weights
|
||||
ln -s -T /models /opt/conda/lib/python3.7/site-packages/realesrgan/weights
|
||||
|
||||
# force facexlib cache
|
||||
mkdir -p /cache/weights/ ${WORKDIR}/gfpgan/
|
||||
ln -sf /cache/weights/ ${WORKDIR}/gfpgan/
|
||||
|
||||
# mount config
|
||||
ln -sf /docker/config.json ${WORKDIR}/config.json
|
||||
9
LICENSE
9
LICENSE
@@ -86,4 +86,11 @@ administration of justice, law enforcement, immigration or asylum
|
||||
processes, such as predicting an individual will commit fraud/crime
|
||||
commitment (e.g. by text profiling, drawing causal relationships between
|
||||
assertions made in documents, indiscriminate and arbitrarily-targeted
|
||||
use).
|
||||
use).
|
||||
|
||||
|
||||
|
||||
By using this software, you also agree to the following licenses:
|
||||
https://github.com/CompVis/stable-diffusion/blob/main/LICENSE
|
||||
https://github.com/TencentARC/GFPGAN/blob/master/LICENSE
|
||||
https://github.com/xinntao/Real-ESRGAN/blob/master/LICENSE
|
||||
|
||||
92
README.md
92
README.md
@@ -1,83 +1,68 @@
|
||||
# Stable Diffusion WebUI Docker
|
||||
# Stable Diffusion WebUI Docker
|
||||
|
||||
Run Stable Diffusion on your machine with a nice UI without any hassle!
|
||||
|
||||
This repository provides the [WebUI](https://github.com/hlky/stable-diffusion-webui) as a docker image for easy setup and deployment.
|
||||
|
||||
Now with experimental support for 2 other forks:
|
||||
|
||||
- [AUTOMATIC1111](./AUTOMATIC1111/) (Stable, very few bugs!)
|
||||
- [lstein](./lstein/)
|
||||
This repository provides multiple UIs for you to play around with stable diffusion:
|
||||
|
||||
## Features
|
||||
|
||||
- Interactive UI with many features, and more on the way!
|
||||
- Support for 6GB GPU cards.
|
||||
- GFPGAN for face reconstruction, RealESRGAN for super-sampling.
|
||||
- Experimental:
|
||||
- Latent Diffusion Super Resolution
|
||||
- GoBig
|
||||
- GoLatent
|
||||
- many more!
|
||||
### AUTOMATIC1111
|
||||
|
||||
## Setup
|
||||
[AUTOMATIC1111's fork](https://github.com/AUTOMATIC1111/stable-diffusion-webui) is imho the most feature rich yet elegant UI:
|
||||
|
||||
Make sure you have an **up to date** version of docker installed. Download this repo and run:
|
||||
- Text to image, with many samplers and even negative prompts!
|
||||
- Image to image, with masking, cropping, in-painting, out-painting, variations.
|
||||
- GFPGAN, RealESRGAN, LDSR, CodeFormer.
|
||||
- Loopback, prompt weighting, prompt matrix, X/Y plot
|
||||
- Live preview of the generated images.
|
||||
- Highly optimized 4GB GPU support, or even CPU only!
|
||||
- Textual inversion allows you to use pretrained textual inversion embeddings
|
||||
- [Full feature list here](https://github.com/AUTOMATIC1111/stable-diffusion-webui-feature-showcase)
|
||||
|
||||
```
|
||||
docker compose build
|
||||
```
|
||||
| Text to image | Image to image | Extras |
|
||||
| ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- |
|
||||
|  |  | 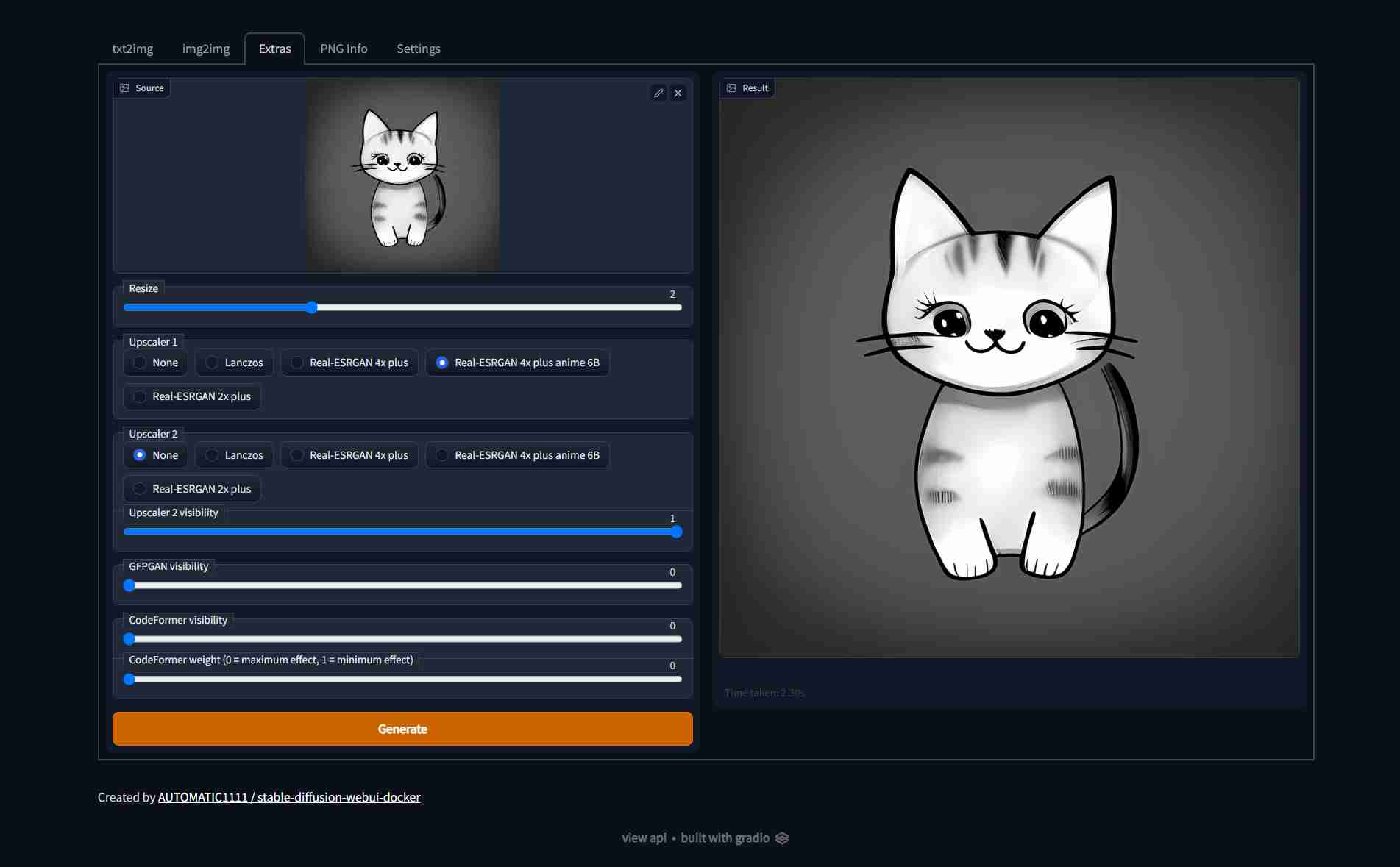 |
|
||||
|
||||
you can let it build in the background while you download the different models
|
||||
### hlky
|
||||
|
||||
- [Stable Diffusion v1.4 (4GB)](https://www.googleapis.com/storage/v1/b/aai-blog-files/o/sd-v1-4.ckpt?alt=media), rename to `model.ckpt`
|
||||
- (Optional) [GFPGANv1.3.pth (333MB)](https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.3.pth).
|
||||
- (Optional) [RealESRGAN_x4plus.pth (64MB)](https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth) and [RealESRGAN_x4plus_anime_6B.pth (18MB)](https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.2.4/RealESRGAN_x4plus_anime_6B.pth).
|
||||
- (Optional) [LDSR (2GB)](https://heibox.uni-heidelberg.de/f/578df07c8fc04ffbadf3/?dl=1) and [its configuration](https://heibox.uni-heidelberg.de/f/31a76b13ea27482981b4/?dl=1), rename to `LDSR.ckpt` and `LDSR.yaml` respectively.
|
||||
<!-- - (Optional) [RealESRGAN_x2plus.pth (64MB)](https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.1/RealESRGAN_x2plus.pth)
|
||||
- TODO: (I still need to find the RealESRGAN_x2plus_6b.pth) -->
|
||||
[hlky's fork](https://github.com/hlky/stable-diffusion-webui) is one of the most popular UIs, with many features:
|
||||
|
||||
Put all of the downloaded files in the `models` folder, it should look something like this:
|
||||
- Text to image, with many samplers
|
||||
- Image to image, with masking, cropping, in-painting, variations.
|
||||
- GFPGAN, RealESRGAN, LDSR, GoBig, GoLatent
|
||||
- Loopback, prompt weighting
|
||||
- 6GB or even 4GB GPU support!
|
||||
- [Full feature list here](https://github.com/sd-webui/stable-diffusion-webui/blob/master/README.md)
|
||||
|
||||
```
|
||||
models/
|
||||
├── model.ckpt
|
||||
├── GFPGANv1.3.pth
|
||||
├── RealESRGAN_x4plus.pth
|
||||
├── RealESRGAN_x4plus_anime_6B.pth
|
||||
├── LDSR.ckpt
|
||||
└── LDSR.yaml
|
||||
```
|
||||
Screenshots:
|
||||
|
||||
## Run
|
||||
| Text to image | Image to image | Image Lab |
|
||||
| ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- |
|
||||
|  |  | 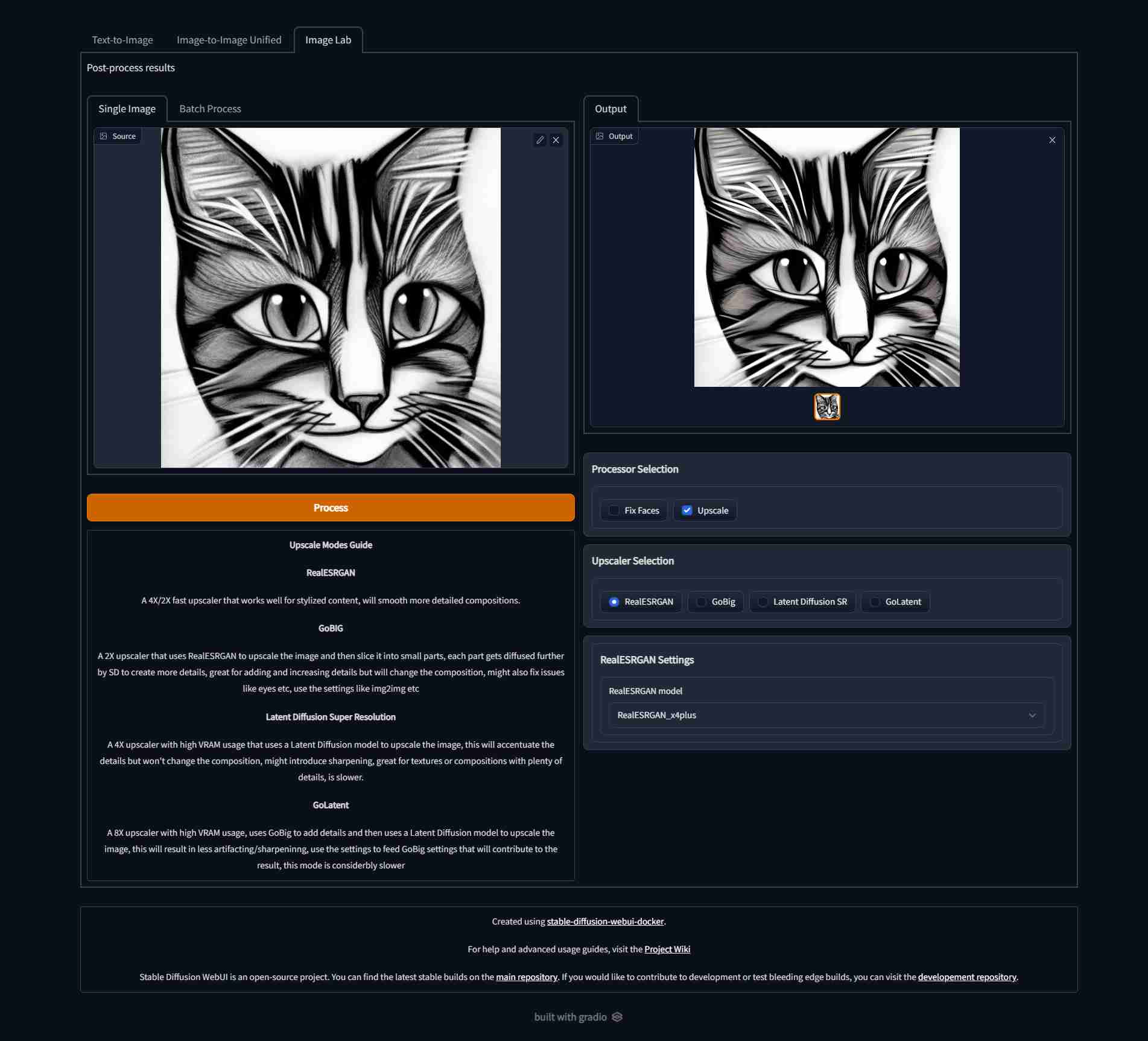 |
|
||||
|
||||
After the build is done, you can run the app with:
|
||||
### lstein
|
||||
|
||||
```
|
||||
docker compose up --build
|
||||
```
|
||||
[lstein's fork](https://github.com/lstein/stable-diffusion) is very mature when it comes to the cli, and the WebUI has potential.
|
||||
|
||||
Will start the app on http://localhost:7860/
|
||||
| Text to image | Image to image | Extras |
|
||||
| ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- |
|
||||
|  |  |  |
|
||||
|
||||
Note: the first start will take sometime as some other models will be downloaded, these will be cached in the `cache` folder, so next runs are faster.
|
||||
## Setup & Usage
|
||||
|
||||
### FAQ
|
||||
Visit the wiki for [Setup](https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/Setup) and [Usage](https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/Usage) instructions, checkout the [FAQ](https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/FAQ) page if you face any problems, or create a new issue!
|
||||
|
||||
You can find fixes to common issues [in the wiki page.](https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/FAQ)
|
||||
## Contributing
|
||||
|
||||
## Config
|
||||
Contributions are welcome! create an issue first of what you want to contribute (before you implement anything) so we can talk about it.
|
||||
|
||||
in the `docker-compose.yml` you can change the `CLI_ARGS` variable, which contains the arguments that will be passed to the WebUI. By default: `--extra-models-cpu --optimized-turbo` are given, which allow you to use this model on a 6GB GPU. However, some features might not be available in the mode. [You can find the full list of arguments here.](https://github.com/hlky/stable-diffusion/blob/bb765f1897c968495ffe12a06b421d97b56d5ae1/scripts/webui.py)
|
||||
|
||||
You can set the `WEBUI_SHA` to [any SHA from the main repo](https://github.com/hlky/stable-diffusion/commits/main), this will build the container against that commit. Use at your own risk.
|
||||
|
||||
# Disclaimer
|
||||
## Disclaimer
|
||||
|
||||
The authors of this project are not responsible for any content generated using this interface.
|
||||
|
||||
This license of this software forbids you from sharing any content that violates any laws, produce any harm to a person, disseminate any personal information that would be meant for harm, spread misinformation and target vulnerable groups. For the full list of restrictions please read [the license](./LICENSE).
|
||||
|
||||
# Thanks
|
||||
## Thanks
|
||||
|
||||
Special thanks to everyone behind these awesome projects, without them, none of this would have been possible:
|
||||
|
||||
@@ -87,3 +72,4 @@ Special thanks to everyone behind these awesome projects, without them, none of
|
||||
- [CompVis/stable-diffusion](https://github.com/CompVis/stable-diffusion)
|
||||
- [hlky/sd-enable-textual-inversion](https://github.com/hlky/sd-enable-textual-inversion)
|
||||
- [devilismyfriend/latent-diffusion](https://github.com/devilismyfriend/latent-diffusion)
|
||||
- [Hafiidz/latent-diffusion](https://github.com/Hafiidz/latent-diffusion)
|
||||
|
||||
4
cache/.gitignore
vendored
4
cache/.gitignore
vendored
@@ -1,3 +1,5 @@
|
||||
/torch
|
||||
/transformers
|
||||
/weights
|
||||
/weights
|
||||
/models
|
||||
/custom-models
|
||||
|
||||
@@ -1,22 +1,11 @@
|
||||
version: '3.9'
|
||||
|
||||
services:
|
||||
model:
|
||||
build:
|
||||
context: ./hlky/
|
||||
args:
|
||||
# You can choose any commit sha from https://github.com/hlky/stable-diffusion/commits/main
|
||||
# USE AT YOUR OWN RISK! otherwise just leave it empty.
|
||||
WEBUI_SHA:
|
||||
restart: on-failure
|
||||
x-base_service: &base_service
|
||||
ports:
|
||||
- "7860:7860"
|
||||
volumes:
|
||||
- ./cache:/cache
|
||||
- ./output:/output
|
||||
- ./models:/models
|
||||
environment:
|
||||
- CLI_ARGS=--extra-models-cpu --optimized-turbo
|
||||
- &v1 ./cache:/cache
|
||||
- &v2 ./output:/output
|
||||
deploy:
|
||||
resources:
|
||||
reservations:
|
||||
@@ -24,3 +13,46 @@ services:
|
||||
- driver: nvidia
|
||||
device_ids: ['0']
|
||||
capabilities: [gpu]
|
||||
|
||||
name: webui-docker
|
||||
|
||||
services:
|
||||
download:
|
||||
build: ./services/download/
|
||||
profiles: ["download"]
|
||||
volumes:
|
||||
- *v1
|
||||
|
||||
hlky:
|
||||
<<: *base_service
|
||||
profiles: ["hlky"]
|
||||
build: ./services/hlky/
|
||||
environment:
|
||||
- CLI_ARGS=--optimized-turbo
|
||||
|
||||
automatic1111: &automatic
|
||||
<<: *base_service
|
||||
profiles: ["auto"]
|
||||
build: ./services/AUTOMATIC1111
|
||||
volumes:
|
||||
- *v1
|
||||
- *v2
|
||||
- ./services/AUTOMATIC1111/config.json:/stable-diffusion-webui/config.json
|
||||
- ./embeddings:/stable-diffusion-webui/embeddings
|
||||
environment:
|
||||
- CLI_ARGS=--allow-code --medvram
|
||||
|
||||
automatic1111-cpu:
|
||||
<<: *automatic
|
||||
profiles: ["auto-cpu"]
|
||||
deploy: {}
|
||||
environment:
|
||||
- CLI_ARGS=--no-half --precision full
|
||||
|
||||
lstein:
|
||||
<<: *base_service
|
||||
profiles: ["lstein"]
|
||||
build: ./services/lstein/
|
||||
environment:
|
||||
- PRELOAD=false
|
||||
- CLI_ARGS=
|
||||
|
||||
@@ -1,71 +0,0 @@
|
||||
# syntax=docker/dockerfile:1
|
||||
|
||||
FROM continuumio/miniconda3:4.12.0
|
||||
|
||||
SHELL ["/bin/bash", "-ceuxo", "pipefail"]
|
||||
|
||||
RUN conda install python=3.8.5 && conda clean -a -y
|
||||
RUN conda install pytorch==1.11.0 torchvision==0.12.0 cudatoolkit=11.3 -c pytorch && conda clean -a -y
|
||||
|
||||
RUN apt-get update && apt install fonts-dejavu-core rsync -y && apt-get clean
|
||||
|
||||
|
||||
RUN <<EOF
|
||||
git clone https://github.com/hlky/stable-diffusion.git
|
||||
cd stable-diffusion
|
||||
git reset --hard c84748aa6802c2f934687883a79bde745d2a58a6
|
||||
conda env update --file environment.yaml -n base
|
||||
conda clean -a -y
|
||||
EOF
|
||||
|
||||
# new dependency, should be added to the environment.yaml
|
||||
RUN pip install -U --no-cache-dir pyperclip
|
||||
|
||||
# Note: don't update the sha of previous versions because the install will take forever
|
||||
# instead, update the repo state in a later step
|
||||
ARG WEBUI_SHA=bb765f1897c968495ffe12a06b421d97b56d5ae1
|
||||
RUN cd stable-diffusion && git pull && git reset --hard ${WEBUI_SHA} && \
|
||||
conda env update --file environment.yaml --name base && conda clean -a -y
|
||||
|
||||
|
||||
# download dev UI version, update the sha below in case you want some other version
|
||||
# RUN <<EOF
|
||||
# git clone https://github.com/hlky/stable-diffusion-webui.git
|
||||
# cd stable-diffusion-webui
|
||||
# # map to this file: https://github.com/hlky/stable-diffusion-webui/blob/master/.github/sync.yml
|
||||
# git reset --hard 49e6178fd82ca736f9bbc621c6b12487c300e493
|
||||
# cp -t /stable-diffusion/scripts/ webui.py relauncher.py txt2img.yaml
|
||||
# cp -t /stable-diffusion/configs/webui webui.yaml
|
||||
# cp -t /stable-diffusion/frontend/ frontend/*
|
||||
# cd / && rm -rf stable-diffusion-webui
|
||||
# EOF
|
||||
|
||||
# Textual inversion
|
||||
RUN <<EOF
|
||||
git clone https://github.com/hlky/sd-enable-textual-inversion.git &&
|
||||
cd /sd-enable-textual-inversion && git reset --hard 08f9b5046552d17cf7327b30a98410222741b070 &&
|
||||
rsync -a /sd-enable-textual-inversion/ /stable-diffusion/ &&
|
||||
rm -rf /sd-enable-textual-inversion
|
||||
EOF
|
||||
|
||||
# Latent diffusion
|
||||
RUN <<EOF
|
||||
git clone https://github.com/devilismyfriend/latent-diffusion &&
|
||||
cd /latent-diffusion &&
|
||||
git reset --hard 6d61fc03f15273a457950f2cdc10dddf53ba6809 &&
|
||||
# hacks all the way down
|
||||
mv ldm ldm_latent &&
|
||||
sed -i -- 's/from ldm/from ldm_latent/g' *.py
|
||||
# dont forget to update the yaml!!
|
||||
EOF
|
||||
|
||||
|
||||
# add info
|
||||
COPY . /docker/
|
||||
RUN python /docker/info.py /stable-diffusion/frontend/frontend.py
|
||||
|
||||
WORKDIR /stable-diffusion
|
||||
ENV TRANSFORMERS_CACHE=/cache/transformers TORCH_HOME=/cache/torch CLI_ARGS=""
|
||||
EXPOSE 7860
|
||||
# run, -u to not buffer stdout / stderr
|
||||
CMD /docker/mount.sh && python3 -u scripts/webui.py --outdir /output --ckpt /models/model.ckpt --ldsr-dir /latent-diffusion ${CLI_ARGS}
|
||||
@@ -1,31 +0,0 @@
|
||||
#!/bin/bash
|
||||
|
||||
set -e
|
||||
|
||||
declare -A MODELS
|
||||
MODELS["/stable-diffusion/src/gfpgan/experiments/pretrained_models/GFPGANv1.3.pth"]=GFPGANv1.3.pth
|
||||
MODELS["/stable-diffusion/src/realesrgan/experiments/pretrained_models/RealESRGAN_x4plus.pth"]=RealESRGAN_x4plus.pth
|
||||
MODELS["/stable-diffusion/src/realesrgan/experiments/pretrained_models/RealESRGAN_x4plus_anime_6B.pth"]=RealESRGAN_x4plus_anime_6B.pth
|
||||
MODELS["/latent-diffusion/experiments/pretrained_models/model.ckpt"]=LDSR.ckpt
|
||||
# MODELS["/latent-diffusion/experiments/pretrained_models/project.yaml"]=LDSR.yaml
|
||||
|
||||
for path in "${!MODELS[@]}"; do
|
||||
name=${MODELS[$path]}
|
||||
base=$(dirname "${path}")
|
||||
from_path="/models/${name}"
|
||||
if test -f "${from_path}"; then
|
||||
mkdir -p "${base}" && ln -sf "${from_path}" "${path}" && echo "Mounted ${name}"
|
||||
else
|
||||
echo "Skipping ${name}"
|
||||
fi
|
||||
done
|
||||
|
||||
# hack for latent-diffusion
|
||||
if test -f /models/LDSR.yaml; then
|
||||
sed 's/ldm\./ldm_latent\./g' /models/LDSR.yaml >/latent-diffusion/experiments/pretrained_models/project.yaml
|
||||
fi
|
||||
|
||||
# force facexlib cache
|
||||
mkdir -p /cache/weights/
|
||||
rm -rf /stable-diffusion/src/facexlib/facexlib/weights
|
||||
ln -sf /cache/weights/ /stable-diffusion/src/facexlib/facexlib/
|
||||
@@ -1,29 +0,0 @@
|
||||
# syntax=docker/dockerfile:1
|
||||
|
||||
FROM continuumio/miniconda3:4.12.0
|
||||
|
||||
SHELL ["/bin/bash", "-ceuxo", "pipefail"]
|
||||
|
||||
RUN conda install python=3.8.5 && conda clean -a -y
|
||||
RUN conda install pytorch==1.11.0 torchvision==0.12.0 cudatoolkit=11.3 -c pytorch && conda clean -a -y
|
||||
|
||||
RUN apt-get update && apt install fonts-dejavu-core rsync -y && apt-get clean
|
||||
|
||||
|
||||
RUN <<EOF
|
||||
git clone https://github.com/lstein/stable-diffusion.git
|
||||
cd stable-diffusion
|
||||
git reset --hard 751283a2de81bee4bb571fbabe4adb19f1d85b97
|
||||
conda env update --file environment.yaml -n base
|
||||
conda clean -a -y
|
||||
EOF
|
||||
|
||||
ENV TRANSFORMERS_CACHE=/cache/transformers TORCH_HOME=/cache/torch CLI_ARGS=""
|
||||
|
||||
WORKDIR /stable-diffusion
|
||||
|
||||
EXPOSE 7860
|
||||
# run, -u to not buffer stdout / stderr
|
||||
CMD mkdir -p /stable-diffusion/models/ldm/stable-diffusion-v1/ && \
|
||||
ln -sf /models/model.ckpt /stable-diffusion/models/ldm/stable-diffusion-v1/model.ckpt && \
|
||||
python3 -u scripts/dream.py --outdir /output --web --host 0.0.0.0 --port 7860 ${CLI_ARGS}
|
||||
@@ -1,14 +0,0 @@
|
||||
# WebUI for lstein
|
||||
|
||||
The WebUI of [lstein/stable-diffusion](https://github.com/lstein/stable-diffusion) as docker container!
|
||||
|
||||
Although it is a simple UI, the project has a lot of potential.
|
||||
|
||||
## Setup
|
||||
|
||||
Clone this repo, download the `model.ckpt` and put into the `models` folder as mentioned in [the main README](../README.md), then run
|
||||
|
||||
```
|
||||
cd lstein
|
||||
docker compose up --build
|
||||
```
|
||||
@@ -1,21 +0,0 @@
|
||||
version: '3.9'
|
||||
|
||||
services:
|
||||
model:
|
||||
build: .
|
||||
restart: on-failure
|
||||
ports:
|
||||
- "7860:7860"
|
||||
volumes:
|
||||
- ../cache:/cache
|
||||
- ../output:/output
|
||||
- ../models:/models
|
||||
environment:
|
||||
- CLI_ARGS=
|
||||
deploy:
|
||||
resources:
|
||||
reservations:
|
||||
devices:
|
||||
- driver: nvidia
|
||||
device_ids: ['0']
|
||||
capabilities: [gpu]
|
||||
7
models/.gitignore
vendored
7
models/.gitignore
vendored
@@ -1,7 +0,0 @@
|
||||
/model.ckpt
|
||||
/GFPGANv1.3.pth
|
||||
/RealESRGAN_x2plus.pth
|
||||
/RealESRGAN_x4plus.pth
|
||||
/RealESRGAN_x4plus_anime_6B.pth
|
||||
/LDSR.ckpt
|
||||
/LDSR.yaml
|
||||
5
scripts/chmod.sh
Executable file
5
scripts/chmod.sh
Executable file
@@ -0,0 +1,5 @@
|
||||
#!/bin/bash
|
||||
|
||||
set -Eeuo pipefail
|
||||
|
||||
find . -name "*.sh" -exec git update-index --chmod=+x {} \;
|
||||
75
services/AUTOMATIC1111/Dockerfile
Normal file
75
services/AUTOMATIC1111/Dockerfile
Normal file
@@ -0,0 +1,75 @@
|
||||
# syntax=docker/dockerfile:1
|
||||
|
||||
FROM alpine/git:2.36.2 as download
|
||||
|
||||
|
||||
RUN git clone https://github.com/CompVis/stable-diffusion.git repositories/stable-diffusion && cd repositories/stable-diffusion && git reset --hard 69ae4b35e0a0f6ee1af8bb9a5d0016ccb27e36dc
|
||||
|
||||
RUN git clone https://github.com/sczhou/CodeFormer.git repositories/CodeFormer && cd repositories/CodeFormer && git reset --hard c5b4593074ba6214284d6acd5f1719b6c5d739af
|
||||
RUN git clone https://github.com/salesforce/BLIP.git repositories/BLIP && cd repositories/BLIP && git reset --hard 48211a1594f1321b00f14c9f7a5b4813144b2fb9
|
||||
RUN git clone https://github.com/Hafiidz/latent-diffusion.git repositories/latent-diffusion && cd repositories/latent-diffusion && git reset --hard abf33e7002d59d9085081bce93ec798dcabd49af
|
||||
|
||||
RUN <<EOF
|
||||
# because taming-transformers is huge
|
||||
git config --global http.postBuffer 1048576000
|
||||
git clone https://github.com/CompVis/taming-transformers.git repositories/taming-transformers
|
||||
git reset --hard 24268930bf1dce879235a7fddd0b2355b84d7ea6
|
||||
rm -rf repositories/taming-transformers/data repositories/taming-transformers/assets
|
||||
EOF
|
||||
|
||||
|
||||
FROM continuumio/miniconda3:4.12.0
|
||||
|
||||
SHELL ["/bin/bash", "-ceuxo", "pipefail"]
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
RUN conda install python=3.8.5 && conda clean -a -y
|
||||
RUN conda install pytorch==1.11.0 torchvision==0.12.0 cudatoolkit=11.3 -c pytorch && conda clean -a -y
|
||||
|
||||
RUN apt-get update && apt install fonts-dejavu-core rsync -y && apt-get clean
|
||||
|
||||
|
||||
RUN <<EOF
|
||||
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
|
||||
cd stable-diffusion-webui
|
||||
git reset --hard 7e77938230d4fefb6edccdba0b80b61d8416673e
|
||||
pip install --prefer-binary --no-cache-dir -r requirements.txt
|
||||
EOF
|
||||
|
||||
ENV ROOT=/stable-diffusion-webui \
|
||||
WORKDIR=/stable-diffusion-webui/repositories/stable-diffusion
|
||||
|
||||
|
||||
COPY --from=download /git/ ${ROOT}
|
||||
RUN pip install --prefer-binary --no-cache-dir -r ${ROOT}/repositories/CodeFormer/requirements.txt
|
||||
|
||||
# Note: don't update the sha of previous versions because the install will take forever
|
||||
# instead, update the repo state in a later step
|
||||
|
||||
ARG SHA=ca3e5519e8b6dc020c5e7ae508738afb5dc6f3ec
|
||||
RUN <<EOF
|
||||
cd stable-diffusion-webui
|
||||
git pull --rebase
|
||||
git reset --hard ${SHA}
|
||||
pip install --prefer-binary --no-cache-dir -r requirements.txt
|
||||
pip install --prefer-binary --no-cache-dir -r requirements_versions.txt
|
||||
EOF
|
||||
|
||||
RUN pip install --prefer-binary -U --no-cache-dir opencv-python-headless
|
||||
|
||||
ENV TRANSFORMERS_CACHE=/cache/transformers TORCH_HOME=/cache/torch CLI_ARGS=""
|
||||
|
||||
COPY . /docker
|
||||
RUN <<EOF
|
||||
chmod +x /docker/mount.sh && python3 /docker/info.py ${ROOT}/modules/ui.py
|
||||
# hackiest of hacks, change default cache dir of clip #88
|
||||
# https://github.com/openai/CLIP/blob/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1/clip/clip.py#L94
|
||||
sed -i -- 's/download_root: str = None/download_root: str = "\/cache\/weights"/' /opt/conda/lib/python3.8/site-packages/clip/clip.py
|
||||
EOF
|
||||
|
||||
WORKDIR ${WORKDIR}
|
||||
EXPOSE 7860
|
||||
# run, -u to not buffer stdout / stderr
|
||||
CMD /docker/mount.sh && \
|
||||
python3 -u ../../webui.py --listen --port 7860 --hide-ui-dir-config --ckpt-dir /cache/custom-models --ckpt /cache/models/model.ckpt --gfpgan-model /cache/models/GFPGANv1.3.pth ${CLI_ARGS}
|
||||
79
services/AUTOMATIC1111/config.json
Normal file
79
services/AUTOMATIC1111/config.json
Normal file
@@ -0,0 +1,79 @@
|
||||
{
|
||||
"outdir_samples": "/output",
|
||||
"outdir_txt2img_samples": "/output/txt2img-images",
|
||||
"outdir_img2img_samples": "/output/img2img-images",
|
||||
"outdir_extras_samples": "/output/extras-images",
|
||||
"outdir_txt2img_grids": "/output/txt2img-grids",
|
||||
"outdir_img2img_grids": "/output/img2img-grids",
|
||||
"outdir_save": "/output/saved",
|
||||
"font": "DejaVuSans.ttf",
|
||||
"__WARNING__": "DON'T CHANGE ANYTHING BEFORE THIS",
|
||||
|
||||
"add_model_hash_to_info": false,
|
||||
"code_former_weight": 0.5,
|
||||
"directories_filename_pattern": "",
|
||||
"directories_max_prompt_words": 8,
|
||||
"enable_batch_seeds": true,
|
||||
"enable_emphasis": true,
|
||||
"enable_pnginfo": true,
|
||||
"enable_quantization": false,
|
||||
"ESRGAN_tile": 192,
|
||||
"ESRGAN_tile_overlap": 8,
|
||||
"export_for_4chan": true,
|
||||
"face_restoration_model": null,
|
||||
"face_restoration_unload": false,
|
||||
"filter_nsfw": false,
|
||||
"grid_extended_filename": false,
|
||||
"grid_format": "png",
|
||||
"grid_only_if_multiple": true,
|
||||
"grid_save": true,
|
||||
"grid_save_to_dirs": false,
|
||||
"img2img_color_correction": false,
|
||||
"img2img_fix_steps": false,
|
||||
"interrogate_clip_dict_limit": 1500,
|
||||
"interrogate_clip_max_length": 48,
|
||||
"interrogate_clip_min_length": 24,
|
||||
"interrogate_clip_num_beams": 1,
|
||||
"interrogate_keep_models_in_memory": false,
|
||||
"interrogate_use_builtin_artists": true,
|
||||
"jpeg_quality": 80,
|
||||
"js_modal_lightbox": true,
|
||||
"js_modal_lightbox_initialy_zoomed": true,
|
||||
"ldsr_post_down": 1,
|
||||
"ldsr_pre_down": 1,
|
||||
"ldsr_steps": 30,
|
||||
"memmon_poll_rate": 8,
|
||||
"multiple_tqdm": true,
|
||||
"n_rows": -1,
|
||||
"outdir_grids": "",
|
||||
"random_artist_categories": [],
|
||||
"realesrgan_enabled_models": [
|
||||
"Real-ESRGAN 4x plus",
|
||||
"Real-ESRGAN 4x plus anime 6B",
|
||||
"Real-ESRGAN 2x plus",
|
||||
"Real-ESRGAN AnimeVideo",
|
||||
"Real-ESRGAN General WDN x4x3",
|
||||
"Real-ESRGAN General x4x3"
|
||||
],
|
||||
"return_grid": true,
|
||||
"samples_filename_format": "",
|
||||
"samples_filename_pattern": "",
|
||||
"samples_format": "png",
|
||||
"samples_log_stdout": false,
|
||||
"samples_save": true,
|
||||
"save_images_before_color_correction": false,
|
||||
"save_images_before_face_restoration": false,
|
||||
"save_selected_only": false,
|
||||
"save_to_dirs": false,
|
||||
"save_to_dirs_prompt_len": 10,
|
||||
"save_txt": false,
|
||||
"sd_model_checkpoint": null,
|
||||
"show_progress_every_n_steps": 7,
|
||||
"show_progressbar": true,
|
||||
"SWIN_tile": 192,
|
||||
"SWIN_tile_overlap": 8,
|
||||
"upscale_at_full_resolution_padding": 16,
|
||||
"upscaler_for_hires_fix": null,
|
||||
"upscaler_for_img2img": null,
|
||||
"use_original_name_batch": false
|
||||
}
|
||||
14
services/AUTOMATIC1111/info.py
Normal file
14
services/AUTOMATIC1111/info.py
Normal file
@@ -0,0 +1,14 @@
|
||||
import sys
|
||||
from pathlib import Path
|
||||
|
||||
file = Path(sys.argv[1])
|
||||
file.write_text(
|
||||
file.read_text()\
|
||||
.replace(' return demo', """
|
||||
with demo:
|
||||
gr.Markdown(
|
||||
'Created by [AUTOMATIC1111 / stable-diffusion-webui-docker](https://github.com/AbdBarho/stable-diffusion-webui-docker/)'
|
||||
)
|
||||
return demo
|
||||
""", 1)
|
||||
)
|
||||
36
services/AUTOMATIC1111/mount.sh
Executable file
36
services/AUTOMATIC1111/mount.sh
Executable file
@@ -0,0 +1,36 @@
|
||||
#!/bin/bash
|
||||
|
||||
set -e
|
||||
|
||||
declare -A MODELS
|
||||
|
||||
MODELS["${ROOT}/GFPGANv1.3.pth"]=GFPGANv1.3.pth
|
||||
MODELS["${WORKDIR}/repositories/latent-diffusion/experiments/pretrained_models/model.chkpt"]=LDSR.ckpt
|
||||
MODELS["${WORKDIR}/repositories/latent-diffusion/experiments/pretrained_models/project.yaml"]=LDSR.yaml
|
||||
|
||||
MODELS_DIR=/cache/models
|
||||
|
||||
for path in "${!MODELS[@]}"; do
|
||||
name=${MODELS[$path]}
|
||||
base=$(dirname "${path}")
|
||||
from_path="${MODELS_DIR}/${name}"
|
||||
if test -f "${from_path}"; then
|
||||
mkdir -p "${base}" && ln -sf "${from_path}" "${path}" && echo "Mounted ${name}"
|
||||
else
|
||||
echo "Skipping ${name}"
|
||||
fi
|
||||
done
|
||||
|
||||
# force realesrgan cache
|
||||
rm -rf /opt/conda/lib/python3.8/site-packages/realesrgan/weights
|
||||
ln -s -T "${MODELS_DIR}" /opt/conda/lib/python3.8/site-packages/realesrgan/weights
|
||||
|
||||
# force facexlib cache
|
||||
mkdir -p /cache/weights/ ${WORKDIR}/gfpgan/
|
||||
ln -sf /cache/weights/ ${WORKDIR}/gfpgan/
|
||||
# code former cache
|
||||
rm -rf ${ROOT}/repositories/CodeFormer/weights/CodeFormer ${ROOT}/repositories/CodeFormer/weights/facelib
|
||||
ln -sf -T /cache/weights ${ROOT}/repositories/CodeFormer/weights/CodeFormer
|
||||
ln -sf -T /cache/weights ${ROOT}/repositories/CodeFormer/weights/facelib
|
||||
|
||||
mkdir -p /cache/torch /cache/transformers /cache/weights /cache/models /cache/custom-models
|
||||
6
services/download/Dockerfile
Normal file
6
services/download/Dockerfile
Normal file
@@ -0,0 +1,6 @@
|
||||
FROM bash:alpine3.15
|
||||
|
||||
RUN apk add parallel aria2
|
||||
COPY . /docker
|
||||
RUN chmod +x /docker/download.sh
|
||||
ENTRYPOINT ["/docker/download.sh"]
|
||||
6
services/download/checksums.sha256
Normal file
6
services/download/checksums.sha256
Normal file
@@ -0,0 +1,6 @@
|
||||
fe4efff1e174c627256e44ec2991ba279b3816e364b49f9be2abc0b3ff3f8556 /cache/models/model.ckpt
|
||||
c953a88f2727c85c3d9ae72e2bd4846bbaf59fe6972ad94130e23e7017524a70 /cache/models/GFPGANv1.3.pth
|
||||
4fa0d38905f75ac06eb49a7951b426670021be3018265fd191d2125df9d682f1 /cache/models/RealESRGAN_x4plus.pth
|
||||
f872d837d3c90ed2e05227bed711af5671a6fd1c9f7d7e91c911a61f155e99da /cache/models/RealESRGAN_x4plus_anime_6B.pth
|
||||
c209caecac2f97b4bb8f4d726b70ac2ac9b35904b7fc99801e1f5e61f9210c13 /cache/models/LDSR.ckpt
|
||||
9d6ad53c5dafeb07200fb712db14b813b527edd262bc80ea136777bdb41be2ba /cache/models/LDSR.yaml
|
||||
20
services/download/download.sh
Executable file
20
services/download/download.sh
Executable file
@@ -0,0 +1,20 @@
|
||||
#!/usr/bin/env bash
|
||||
|
||||
set -Eeuo pipefail
|
||||
|
||||
mkdir -p /cache/torch /cache/transformers /cache/weights /cache/models /cache/custom-models
|
||||
|
||||
cat <<EOF
|
||||
By using this software, you agree to the following licenses:
|
||||
https://github.com/CompVis/stable-diffusion/blob/main/LICENSE
|
||||
https://github.com/TencentARC/GFPGAN/blob/master/LICENSE
|
||||
https://github.com/xinntao/Real-ESRGAN/blob/master/LICENSE
|
||||
EOF
|
||||
|
||||
echo "Downloading, this might take a while..."
|
||||
|
||||
aria2c --input-file /docker/links.txt --dir /cache/models --continue
|
||||
|
||||
echo "Checking SHAs..."
|
||||
|
||||
parallel --will-cite -a /docker/checksums.sha256 "echo -n {} | sha256sum -c"
|
||||
12
services/download/links.txt
Normal file
12
services/download/links.txt
Normal file
@@ -0,0 +1,12 @@
|
||||
https://www.googleapis.com/storage/v1/b/aai-blog-files/o/sd-v1-4.ckpt?alt=media
|
||||
out=model.ckpt
|
||||
https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.3.pth
|
||||
out=GFPGANv1.3.pth
|
||||
https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth
|
||||
out=RealESRGAN_x4plus.pth
|
||||
https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.2.4/RealESRGAN_x4plus_anime_6B.pth
|
||||
out=RealESRGAN_x4plus_anime_6B.pth
|
||||
https://heibox.uni-heidelberg.de/f/31a76b13ea27482981b4/?dl=1
|
||||
out=LDSR.yaml
|
||||
https://heibox.uni-heidelberg.de/f/578df07c8fc04ffbadf3/?dl=1
|
||||
out=LDSR.ckpt
|
||||
50
services/hlky/Dockerfile
Normal file
50
services/hlky/Dockerfile
Normal file
@@ -0,0 +1,50 @@
|
||||
# syntax=docker/dockerfile:1
|
||||
|
||||
FROM continuumio/miniconda3:4.12.0
|
||||
|
||||
SHELL ["/bin/bash", "-ceuxo", "pipefail"]
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
RUN conda install python=3.8.5 && conda clean -a -y
|
||||
RUN conda install pytorch==1.11.0 torchvision==0.12.0 cudatoolkit=11.3 -c pytorch && conda clean -a -y
|
||||
|
||||
RUN apt-get update && apt install fonts-dejavu-core rsync gcc -y && apt-get clean
|
||||
|
||||
|
||||
RUN <<EOF
|
||||
git config --global http.postBuffer 1048576000
|
||||
git clone https://github.com/sd-webui/stable-diffusion-webui.git stable-diffusion
|
||||
cd stable-diffusion
|
||||
git reset --hard 7623a5734740025d79b710f3744bff9276e1467b
|
||||
conda env update --file environment.yaml -n base
|
||||
conda clean -a -y
|
||||
EOF
|
||||
|
||||
|
||||
# Note: don't update the sha of previous versions because the install will take forever
|
||||
# instead, update the repo state in a later step
|
||||
# ARG BRANCH=master SHA=d0bb60a139d60e6c2b9be4e18e0e29a86aa5af59
|
||||
ARG BRANCH=dev SHA=1fd28eed1ebc3aa04b9b00e2a899f3bf07f64bdc
|
||||
RUN <<EOF
|
||||
cd stable-diffusion
|
||||
git fetch
|
||||
git checkout ${BRANCH}
|
||||
git reset --hard ${SHA}
|
||||
conda env update --file environment.yaml -n base
|
||||
conda clean -a -y
|
||||
EOF
|
||||
|
||||
RUN pip install -U --no-cache-dir pyperclip
|
||||
|
||||
# add info
|
||||
COPY . /docker/
|
||||
RUN python /docker/info.py /stable-diffusion/frontend/frontend.py && chmod +x /docker/mount.sh
|
||||
|
||||
WORKDIR /stable-diffusion
|
||||
ENV TRANSFORMERS_CACHE=/cache/transformers TORCH_HOME=/cache/torch PYTHONPATH="${PYTHONPATH}:${PWD}" CLI_ARGS=""
|
||||
EXPOSE 7860
|
||||
# run, -u to not buffer stdout / stderr
|
||||
CMD /docker/mount.sh && \
|
||||
python3 -u scripts/webui.py --outdir /output --ckpt /cache/models/model.ckpt ${CLI_ARGS}
|
||||
# STREAMLIT_SERVER_PORT=7860 python -m streamlit run scripts/webui_streamlit.py --theme.base dark
|
||||
33
services/hlky/mount.sh
Executable file
33
services/hlky/mount.sh
Executable file
@@ -0,0 +1,33 @@
|
||||
#!/bin/bash
|
||||
|
||||
set -e
|
||||
|
||||
declare -A MODELS
|
||||
|
||||
ROOT=/stable-diffusion/src
|
||||
|
||||
MODELS["${ROOT}/gfpgan/experiments/pretrained_models/GFPGANv1.3.pth"]=GFPGANv1.3.pth
|
||||
MODELS["${ROOT}/realesrgan/experiments/pretrained_models/RealESRGAN_x4plus.pth"]=RealESRGAN_x4plus.pth
|
||||
MODELS["${ROOT}/realesrgan/experiments/pretrained_models/RealESRGAN_x4plus_anime_6B.pth"]=RealESRGAN_x4plus_anime_6B.pth
|
||||
MODELS["${ROOT}/latent-diffusion/experiments/pretrained_models/model.ckpt"]=LDSR.ckpt
|
||||
MODELS["${ROOT}/latent-diffusion/experiments/pretrained_models/project.yaml"]=LDSR.yaml
|
||||
|
||||
MODELS_DIR=/cache/models
|
||||
|
||||
for path in "${!MODELS[@]}"; do
|
||||
name=${MODELS[$path]}
|
||||
base=$(dirname "${path}")
|
||||
from_path="${MODELS_DIR}/${name}"
|
||||
if test -f "${from_path}"; then
|
||||
mkdir -p "${base}" && ln -sf "${from_path}" "${path}" && echo "Mounted ${name}"
|
||||
else
|
||||
echo "Skipping ${name}"
|
||||
fi
|
||||
done
|
||||
|
||||
# force facexlib cache
|
||||
mkdir -p /cache/weights/ /stable-diffusion/gfpgan/
|
||||
ln -sf /cache/weights/ /stable-diffusion/gfpgan/
|
||||
|
||||
# streamlit config
|
||||
ln -sf /docker/userconfig_streamlit.yaml /stable-diffusion/configs/webui/userconfig_streamlit.yaml
|
||||
8
services/hlky/userconfig_streamlit.yaml
Normal file
8
services/hlky/userconfig_streamlit.yaml
Normal file
@@ -0,0 +1,8 @@
|
||||
general:
|
||||
outdir: /outputs
|
||||
default_model: "Stable Diffusion v1.4"
|
||||
default_model_path: /cache/models/model.ckpt
|
||||
outdir_txt2img: /outputs/txt2img-samples
|
||||
outdir_img2img: /outputs/img2img-samples
|
||||
optimized: True
|
||||
optimized_turbo: True
|
||||
56
services/lstein/Dockerfile
Normal file
56
services/lstein/Dockerfile
Normal file
@@ -0,0 +1,56 @@
|
||||
# syntax=docker/dockerfile:1
|
||||
|
||||
FROM continuumio/miniconda3:4.12.0
|
||||
|
||||
SHELL ["/bin/bash", "-ceuxo", "pipefail"]
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
# now it requires python3.9
|
||||
RUN conda install python=3.9 && conda clean -a -y
|
||||
RUN conda install pytorch==1.11.0 torchvision==0.12.0 cudatoolkit=11.3 -c pytorch && conda clean -a -y
|
||||
|
||||
RUN apt-get update && apt install fonts-dejavu-core rsync gcc -y && apt-get clean
|
||||
|
||||
|
||||
RUN <<EOF
|
||||
git clone https://github.com/invoke-ai/InvokeAI.git stable-diffusion
|
||||
cd stable-diffusion
|
||||
git reset --hard a1739a73b48bfe98b6abcb67f5a0197a9ad270e0
|
||||
sed -i -- 's/python=3.8.5/python=3.9/g' environment.yaml
|
||||
conda env update --file environment.yaml -n base
|
||||
conda clean -a -y
|
||||
EOF
|
||||
|
||||
|
||||
ARG BRANCH=development SHA=b40bfb5116b7fc618f78a0d152005ceb46153443
|
||||
# this breaks on generation:
|
||||
# there is a new UI anyway, but it is not by any means ready.
|
||||
# ARG BRANCH=development SHA=bdbc76fcd4bd3362312dc91b087d9af66de423b1
|
||||
RUN <<EOF
|
||||
cd stable-diffusion
|
||||
git fetch
|
||||
git reset --hard
|
||||
git checkout ${BRANCH}
|
||||
git reset --hard ${SHA}
|
||||
conda env update --file environment.yaml -n base
|
||||
conda clean -a -y
|
||||
EOF
|
||||
|
||||
RUN pip uninstall opencv-python -y && pip install --prefer-binary --force-reinstall --no-cache-dir opencv-python-headless transformers==4.19.2
|
||||
|
||||
COPY . /docker/
|
||||
RUN <<EOF
|
||||
python3 /docker/info.py /stable-diffusion/static/dream_web/index.html
|
||||
chmod +x /docker/mount.sh
|
||||
sed -i -- 's/outputs\//\/output/g' /stable-diffusion/backend/server.py
|
||||
EOF
|
||||
|
||||
|
||||
ENV TRANSFORMERS_CACHE=/cache/transformers TORCH_HOME=/cache/torch PRELOAD=false CLI_ARGS=""
|
||||
WORKDIR /stable-diffusion
|
||||
EXPOSE 7860
|
||||
|
||||
CMD /docker/mount.sh && \
|
||||
python3 -u scripts/dream.py --outdir /output --web --host 0.0.0.0 --port 7860 ${CLI_ARGS}
|
||||
# python3 -u backend/server.py --host 0.0.0.0 --port 9090
|
||||
10
services/lstein/info.py
Normal file
10
services/lstein/info.py
Normal file
@@ -0,0 +1,10 @@
|
||||
import sys
|
||||
from pathlib import Path
|
||||
|
||||
file = Path(sys.argv[1])
|
||||
file.write_text(
|
||||
file.read_text()\
|
||||
.replace('GitHub site</a>', """
|
||||
GitHub site</a>, Deployed with <a href="https://github.com/AbdBarho/stable-diffusion-webui-docker/">stable-diffusion-webui-docker</a>
|
||||
""", 1)
|
||||
)
|
||||
29
services/lstein/mount.sh
Executable file
29
services/lstein/mount.sh
Executable file
@@ -0,0 +1,29 @@
|
||||
#!/bin/bash
|
||||
|
||||
set -eu
|
||||
|
||||
ROOT=/stable-diffusion
|
||||
|
||||
mkdir -p "${ROOT}/models/ldm/stable-diffusion-v1/"
|
||||
ln -sf /cache/models/model.ckpt "${ROOT}/models/ldm/stable-diffusion-v1/model.ckpt"
|
||||
|
||||
base="${ROOT}/src/gfpgan/experiments/pretrained_models/"
|
||||
mkdir -p "${base}"
|
||||
# TODO: "real" GFPGANv1.4.pth
|
||||
ln -sf /cache/models/GFPGANv1.3.pth "${base}/GFPGANv1.4.pth"
|
||||
echo "Mounted GFPGANv1.3.pth"
|
||||
|
||||
# facexlib
|
||||
FACEX_WEIGHTS=/opt/conda/lib/python3.9/site-packages/facexlib/weights
|
||||
|
||||
rm -rf "${FACEX_WEIGHTS}"
|
||||
mkdir -p /cache/weights
|
||||
ln -sf -T /cache/weights "${FACEX_WEIGHTS}"
|
||||
|
||||
REALESRGAN_WEIGHTS=/opt/conda/lib/python3.9/site-packages/realesrgan/weights
|
||||
rm -rf "${REALESRGAN_WEIGHTS}"
|
||||
ln -sf -T /cache/weights "${REALESRGAN_WEIGHTS}"
|
||||
|
||||
if "${PRELOAD}" == "true"; then
|
||||
python3 -u scripts/preload_models.py
|
||||
fi
|
||||
Reference in New Issue
Block a user